
YOLO: You Only Look Once
이 글은 제가 『YOLO: You Only Look Once』를 공부하면서, 정리한 포스트입니다. 지적과 조언은 언제나 환영입니다 ㅎㅎ
<YOLO>는 대표적인 1-stage detector 중 하나이다. 2-stage detector인 <Fast R-CNN>이 “CNN + RPN”로, 2개의 네트워크로 구성되어 있다면, 1-stage detector인 <YOLO>은 단일 네트워크로 구성되어 있다. 단일 네트워크 모델이기 때문에, “end-to-end” 학습이 가능하다!
Model: Unified Detection
먼저, <YOLO> 모델의 핵심 아이디어인 <Unified Detection>을 바로 살펴보자. 원리는 생각보다 간단하고, 직관적이다.
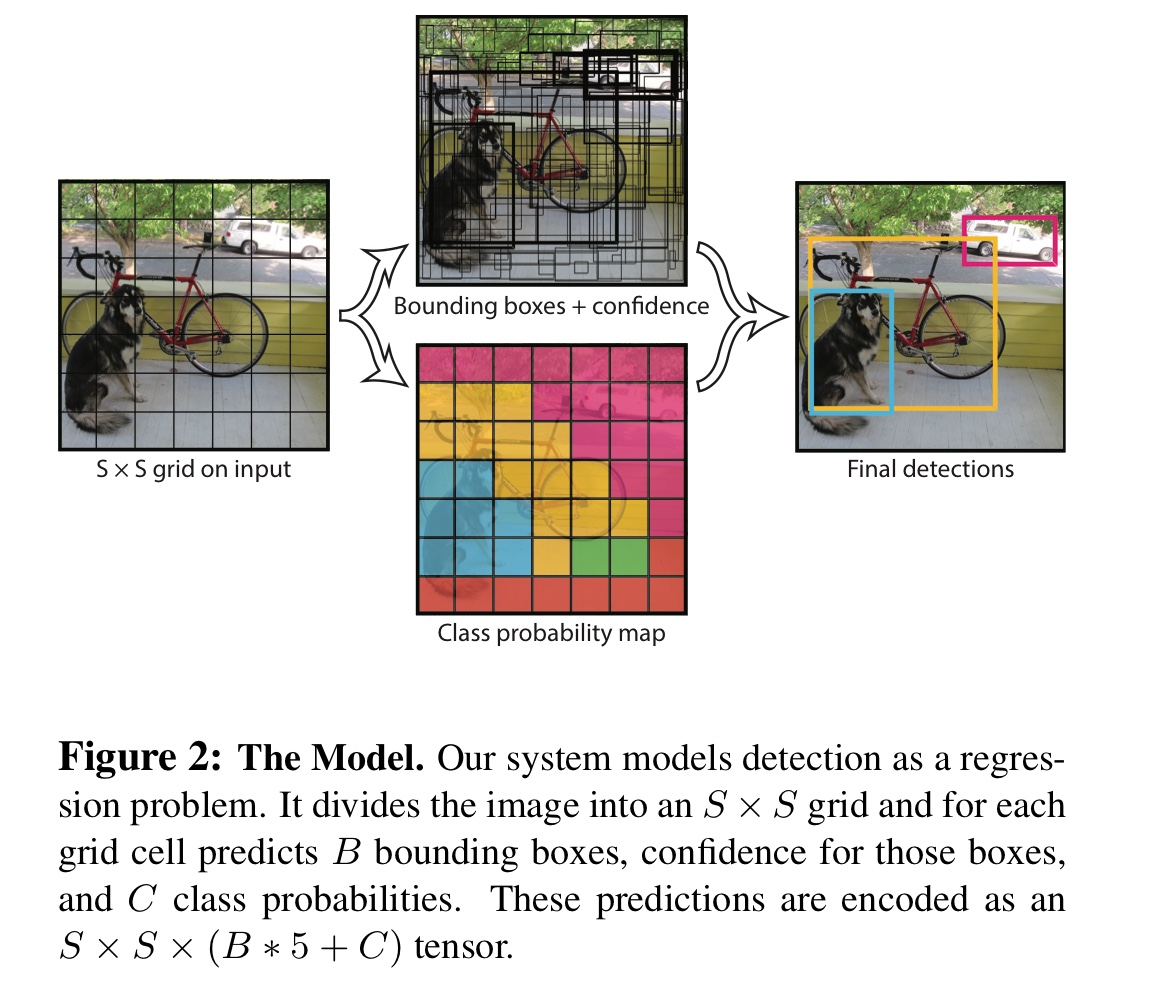
먼저, 이미지를 $S \times S$의 그리드(Grid)로 분할한다. 논문에서는 $S=7$의 값을 사용했다. (왼쪽 그림)
다음으로 Grid cell 하나하나에 대해 “bounding box”과 “confidence”가 담긴 vector를 예측한다. “confidence”는 $[0, 1]$의 값이며, “bounding box”는 $(cx, cy, w, h)$의 형식이다. 그래서 총 5차원의 vector를 예측한다.
이때, 각 Grid cell에서 몇개의 vector를 예측할 지를 결정할 수 있다. 논문에서는 $B=2$로 설정해, Grid cell마다 2개의 bbox와 confidence의 vector를 예측하도록 설정했다. (가운데의 윗그림)
마지막으로, 각 Grid cell에 어떤 물체가 들어있을지 분류(Clssification)하는 작업을 수행한다. 논문에서는 전체 라벨의 수 $C$가 $C=20$인 데이터셋을 사용했다. (가운데의 아랫그림)
마지막으로 이 두 결과를 종합하고, 또 적당히 NMS를 수행해 실제 Prediction output를 출력한다. 그리고 이 output를 바탕으로 loss를 매겨 모델을 학습시킨다. (오른쪽 그림)
결국 <YOLO>는 Detection에 필요한 두 과정인 “Localization”과 “Classification”을 Regression의 관점에서 접근해 한번에 해결 해버렸다!! 😲
사실 지금은 “Localization + Classification”을 한번에 수행하는 1-stage 모델1이 많이 제시되어서, <YOLO> 모델의 접근이 다소 번거로워 보이지만, <YOLO>가 나왔을 당시인 2015년에는 정말 HOT🔥한 모델이었다.
Why YOLO
<YOLO>가 주목받는 이유는 1-stage 모델의 길을 제시했다는 것 뿐만 아니라, 여러가지가 있다.
1. 빠른 Inference
이미지를 입력으로 넣어줬을 때, 그 결과가 아주 빠르게 출력된다는 말이다. 그래서 Real-Time으로 Detection을 수행할 수 있다. 사실상 <YOLO> 이후의 대부분의 1-stage 모델에서는 Real-Time Detection이 가능하다.
2. 이미지를 global하게 파악
기존의 “sliding window” 방식과 “region proposal” 방식과 다르게, 이미지의 전체를 보고 판단한다고 한다. 그래서 Fast R-CNN보다 background error가 더 낮다.
3. 일반화가 쉽다
어떤 데이터셋으로 pre-train 시킨 모델을 사용해 다른 데이터셋을 학습시켜도 잘 동작한다고 한다.
실습
본인은 <YOLOv3>, <YOLOv5> 모델을 사용해봤다. 경험에 비추어 봤을 때, <YOLO> 모델은 정말 좋은 성능을 뱉어서 모델을 실행시키면 기분이 좋았다 😁
개인적으로 ‘빵형의 개발도상국’ 유튜브의 영상이 YOLOv5를 처음 입문하기 좋은 영상인 것 같다.
References
-
대표적으로 <ExtremeNet>, <CenterNet> 등이 있다. ↩