
RNN & LSTM
2020-2학기 “연구참여(CSED339A)”에서 진행한 “Stanford CS231” 스터디에서 공부한 내용을 정리한 포스트입니다. 지적은 언제나 환영입니다 :)
Introduction to Sequential Model
이번 포스트에서 다루는 모델은 “순서”라는 성질을 가진 데이터를 처리하는 모델들이다. 예를 들면, 단어(word)나 문장(sentence), 1년간의 주식 가격 등이 순서가 중요하게 여겨지는 데이터들이다. 이런 데이터를 <sequence data>라고 한다.
기존 <Feed Forward Network>는 값이 전방(前方)으로만 흐르기 때문에 과거의 정보도 중요한 <sequential data>를 처리하기에는 적합하지 않았다. 그러나 <RNN>, <LSTM>은 값이 그 시퀀셜(sequential)한 구조로 인해 과거 데이터의 history를 ‘기억’할 수 있으며, <sequence data>를 처리하는 것에 특화되어 있다.
RNN; Recurrent Neural Network

<RNN; Recurrent Neural Network>에서는 은닉층에서 계산한 값이 출력층 방향으로도 전파되지만, 다시 은닉층으로 돌아와 은닉층의 hidden state에 저장된다. 이 값은 다음 입력을 처리할 때 활용된다!
<RNN>을 위와 같이 표현할 수도 있지만, 아래와 같이 iteration을 풀어서 표현할 수도 있다. 이것을 <Cell>이라고 한다.


은닉층은 $t$시점에서의 출력 $h_t$를 구하기 위해 두 가지 값을 활용한다.
- 이전 시점의 hidden state $h_{t-1}$
- 현재 시점의 입력 $x_t$
이 두 값을 가중치와 함께 잘 조합해 $\tanh$ 함수를 활성 함수 삼아 출력하면, 은닉층의 출력 $h_t$가 된다.
\[h_t = \tanh (W_x x_t + W_h h_{t-1})\]출력층은 이 은닉층의 결과 $h_t$를 입력받아 출력층의 가중치 $W_y$와 조합해 $y_t$를 출력한다.
\[y_t = W_y h_t\]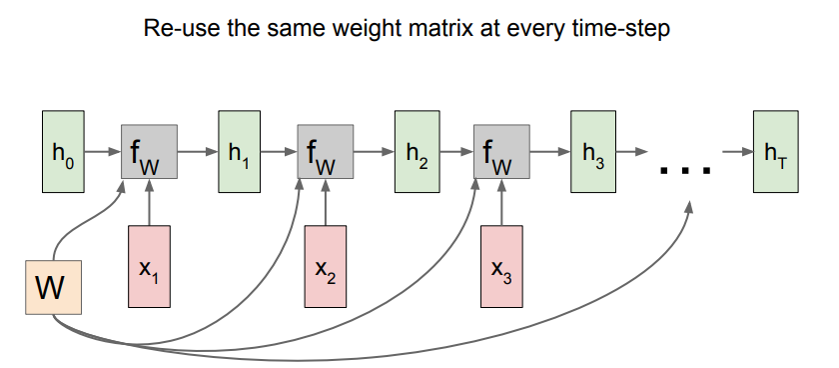
하나의 <Cell>은 학습 데이터의 sequence 하나를 읽을 때까지 모두 동일한 weight 값을 사용한다. 예를 들어 “I love you”라는 데이터를 입력하면, 각 문자는 모두 동일한 weight $W_x$, $W_h$, $W_y$를 사용한다. 그래서 “I love you” 문장 하나가 하나의 데이터 입력이며, Back-propagation 역시 이 한 문장을 다 읽은 후에 일어나는 것이다.
<RNN>에서의 Back-propagation은 기존의 <Feed Forward Network>의 방식과는 조금 다르다. <RNN>에서는 time-step으로 <Cell>을 펼친 후에 Back-prop을 적용한다. 이를 <Backprop Through Time; BPTT>라고 한다.
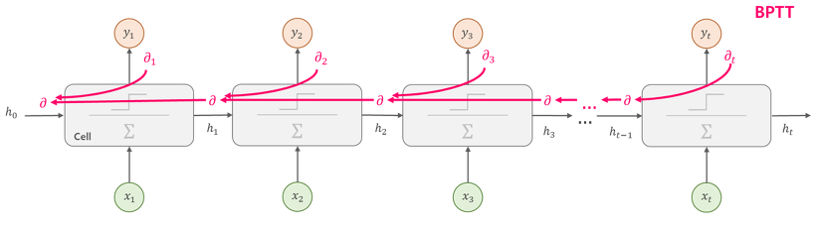
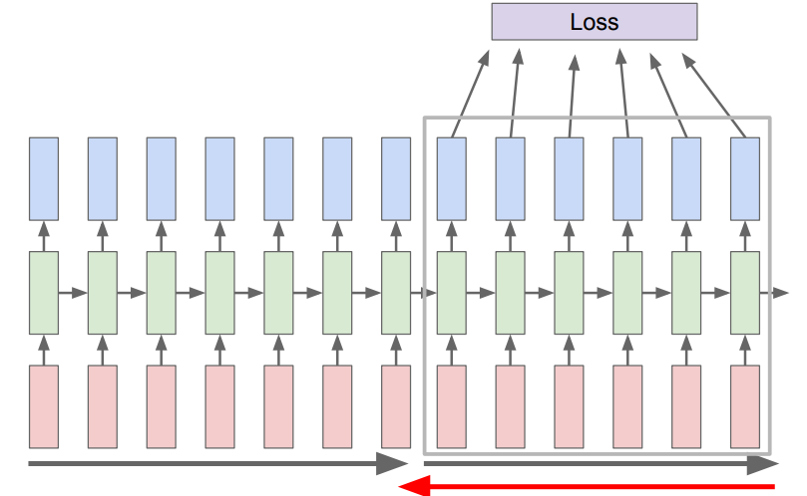
그러나 위와 같은 방식은 처음부터 끝까지 역전파를 문자의 길이가 길어진다면 계산량이 증가한다는 문제가 있다. 이를 해결하기 위해 전체 문장을 일정 구간을 나눠서 Backprop을 수행하기도 한다. 이것을 <Truncated BPTT>라고 한다.
또, <RNN>과 같은 <Sequential Model>은 입력과 출력의 대응에 따라 1-to-1, 1-to-many, many-to-1, many-to-many 등 다양한 형태로 존재한다.

LSTM; Long Short Term Memory model
<RNN>의 경우 hidden state를 통해 이전 입력에 대한 정보를 가지고 있지만, 입력 시퀀스가 길어질수록 성능이 떨어진다는 단점이 존재한다. 이를 <The problem of learning long-term dependencies; 장기 의존성 문제>라고 한다. 이에 대해선 동일한 값의 $W_h$의 값을 여러번 사용하게 되면서 발생하는 Gradient Exploding 또는 Gradient Vanishing을 원인으로 꼽는다.

<LSTM>은 <장기 의존성 문제>를 해결하기 위해 <RNN>의 구조에 Cell state $c_t$를 추가하고 여러 게이트(gate)를 추가한 모델이다.
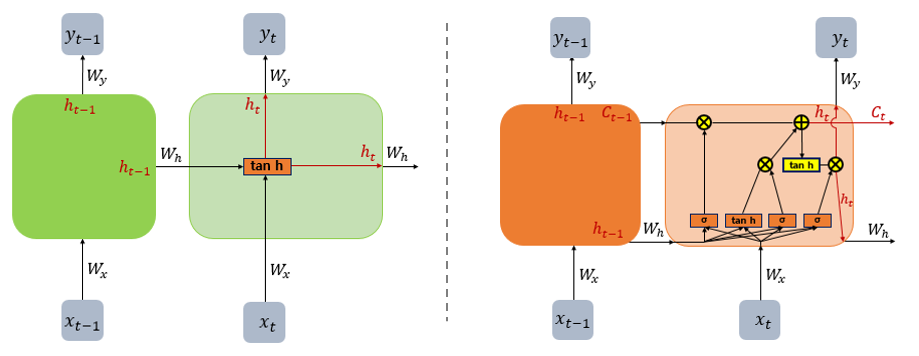
RNN(左)과 LSTM(右)
<LSTM>에서 cell state $c_t$는 장기 기억을 담당하며, hidden state $h_t$는 단기 기억을 담당한다.
\[c_t = f_t \circ c_{t-1} + i_t \circ g_t\] \[h_t = o_t \circ \tanh(c_t)\]<LSTM>에는 4가지 게이트(gate)가 존재하면 각각은 아래와 같다. 편의를 위해 bias $b$ 텀은 생략하였다.
1. 입력 게이트
\[i_t = \sigma(W_{xi} x_t + W_{hi} h_{t-1})\]2. 게이트 게이트 😵
\[g_t = \tanh(W_{xg} x_t + W_{hg}h_{t-1})\]두 게이트 모두 현재의 입력 $x_t$와 hidden state $h_{t-1}$를 입력으로 받으며, 다른 점은 활성화 함수 뿐이다. 이 두 게이트를 통해 현재의 입력에서 기억할 정보의 양을 정한다.
3. 망각 게이트
\[f_t = \sigma(W_{xf} x_t + W_{hf}h_{t-1})\]망각 게이트의 값을 통해 cell state $c_{t-1}$에서 잊을 정보의 양을 정한다.
다시 cell state $c_t$의 수식을 살펴보자. 망각 게이트 $f_t$를 통해 이전 cell state $c_{t-1}$에서 기억할 정보를 결정하고, 입력 게이트 $i_t$와 게이트 게이트 $g_t$를 통해 현재 입력앞에서 기억할 정보를 결정한다. 🤩
\[c_t = f_t \circ c_{t-1} + i_t \circ g_t\]4. 출력 게이트
\[o_t = \sigma(W_{xo} x_t + W_{ho} h_{t-1})\]출력 게이트의 값은 <Cell>의 출력이 되며, 이후 출력층에서 $y$의 값을 구하는데 사용된다. 또, 출력 게이트의 값을 통해 cell state $c_t$에서 단기적으로 기억할 정보를 결정한다.
\[h_t = o_t \circ \tanh(c_t)\]<LSTM>의 경우 <RNN>에 비해 구조가 정말 복잡하지만, 이전과 달리 Gradient Exploding이나 Gradient Vanishing 현상이 두드러지지 않는다! 😁 자세한 이유를 알고 싶다면, 이 아티클을 참고하라.
2014년에는 <LSTM>을 개선한 <GRU; Gated Recurrent Unit>라는 sequential model이 제시되었다. <LSTM>처럼 게이트(gate)가 달려있지만, $h_t$ 하나의 상태만을 기억하기 때문에 <LSTM>보다 더 빠르게 학습한다고 한다. <GRU>에 대한 자세한 내용은 이 아티클을 참고하라.
<RNN>, <LSTM>은 자연어(Natural Language)와 시계열 데이터를 처리하는 가장 기본이 되는 모델이다. 그러니 이번 내용에 익숙해지는 것을 추천한다.
■ related post
- NLP with PyTorch Cheat Sheet