
PageRank Algorithm
머릿말
페이지랭크(PageRank) 알고리즘은 구글의 초기 검색 엔진에 사용된 알고리즘이다. 구글의 창업자 세르게이 브린(Sergey Brin)과 래리 페이지(Larry Page)의 논문이기에 구글이란 회사가 시작되는 알고리즘인 셈이다.
페이지랭크 알고리즘은 논문의 인용(citation) 방식을 웹 페이지에 적용한 알고리즘으로, 특정 페이지가 얼마나 중요한지를 알 수 있다.
PageRank Formula

PageRank 알고리즘의 논문 "The PageRank Citation Ranking: Bringing Order to the Web"의 Reference 문단
논문에선 피인용수가 그 논문의 영향력이다. 웹페이지도 같은 방식으로 중요도를 측정할 수 있지 않을까? 어떤 페이지를 인용하는 다른 페이지가 많다면, 그 페이지는 중요한 페이지 일 것이다!
그러나 대학원생이 고생해서 출판하는 논문과 달리 웹페이지는 아주 쉽게 만들어진다. 누구나 웹페이지를 만들 수 있고, 다른 웹페이지의 링크를 걸 수 있다. 이런 이유로 페이지랭크 알고리즘은 다른 페이지에 오는 링크를 모두 같은 비중으로 세는 것이 아니라 해당 페이지에 걸린 링크 숫자를 정규화(normalize)해 사용한다.
$A$ 페이지의 페이지랭크 $\text{PR}(A)$의 공식을 살펴보자. $T_1, T_2, …, T_n$은 $A$ 페이지를 인용하는 다른 페이지들을 의미하며, $C(T_i)$는 $T_i$ 페이지에 존재하는 링크의 총 갯수이다.
\[\text{PR}(A) = \sum^N_{i=1} \frac{\text{PR}(T_i)}{C(T_i)}\]즉, 어떤 페이지의 페이지랭크는 ‘그 페이지를 인용하는 다른 페이지의 정규화된 페이지랭크의 총합’이다!
왜 정규화된 페이지랭크를 쓰는가?
페이지랭크는 인용 페이지 $T_i$의 페이지랭크 $\text{PR}(T_i)$를 그대로 쓰는게 아니라 정규화된 $\text{PR}(T_i) / C(T_i)$를 사용한다. 그 이유를 살펴보자.
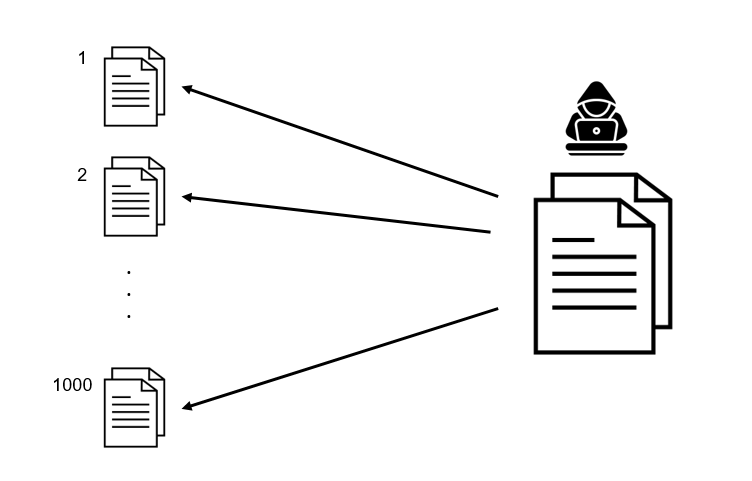
인용 페이지의 페이지랭크를 정규화하지 않는다면,
링크 수천개를 달아 피인용 페이지의 페이지랭크를 고의로 높일 수 있다.
해커가 페이지랭크 알고리즘을 교란하기 위한 수천 개의 외부 링크가 있는 더미 페이지를 만들었다고 상상해보자. 그렇다면 더미 페이지가 인용한 페이지의 페이지랭크는 꽤 높아지고 말 것이다. 이런 더미 페이지의 효과를 완화하기 위해 인용 페이지에 존재하는 링크 수 $C(T_i)$를 사용해 페이지랭크 값을 정규화한다.
인용 페이지의 페이지랭크를 어떻게 구하는가?
간단하다. 페이지랭크의 공식을 인용 페이지 $T_i$에 적용하면 된다. 그러려면 $T_i$ 페이지를 인용하는 다른 페이지들의 페이지랭크를 구하고 … 이렇게 어떤 페이지의 PR을 구하려면 인용 페이지의 PR을 구해야 한다. 재귀적으로 말이다!
def PageRank(A):
pageRank = 0
for page in A.inbounds:
link_cnt = len(page.links)
pageRank += (PageRank(page) / link_cnt)
return pageRank
PageRank()라는 함수를 PageRank() 함수 내부에서 또 호출하는 재귀적 구조를 가지고 있다. 그러나 재귀 연산을 끝까지 하는 비용이 아깝기 때문에 보통은 어느 깊이까지 재귀 연산을 할 것인지 제한을 두고 인용 페이지의 PR을 구한다.
Damping Factor
페이지랭크 알고리즘은 damping factor $d$를 $[0, 1]$의 값을 갖는다. damping factor를 포함해 식을 다시 써보면 아래와 같다.
\[\text{PR}(A) = (1-d) + d \cdot \sum^N_{i=1} \frac{\text{PR}(T_i)}{C(T_i)}\]damping factor $d$의 양 극단인 $0$와 $1$을 살펴보자.
- $d=0$이라면, 모든 페이지의 PR이 $1$이 된다.
- $d=1$이라면, 재귀적으로 동작하는 PR을 그래도 사용한다.
그런데 왜 이런 damping factor $d$를 도입한 것일까? 웹서핑을 하는데 $p = 0.8$의 확률로 다른 페이지로 이동하는 사람이 있다고 생각해보자. 그 사람은 현재의 페이지에서 멈추거나 이동한다. 만약 그 확률이 $p = 1$이라면, 페이지에 존재하는 모든 페이지를 끝없이 클릭해 웹서핑을 이어가는 것이고, 확률이 $p = 0$이라면 처음 방문한 페이지에서 무조건 멈추고 더 이동하지 않는다.
damping factor $d$가 곧 위에서 묘사한 “다른 페이지로 이동할 확률 $p$”이다. 그리고 PageRank $\text{PR}(A)$는 이 확률의 평균을 낸 것이다. 지극히 확률론적!
저자 세르게이의 말에 따르면 모든 웹페이지의 페이지랭크 값을 더한 총합은 $1$이 된다고 한다.
\[\sum_A \text{PR}(A) = 1\]그런데 위의 수식에서 $d=0$인 경우, 모든 페이지의 PR이 $1$이 되기 때문에, 총합을 구하면 $\sum \text{PR}(A) = N$이 된다. 그래서 수식을 약간 수정한 최종적인 형태는 아래와 같다.
\[\text{PR}(A) = \frac{(1-d)}{N} + d \cdot \sum^N_{i=1} \frac{\text{PR}(T_i)}{C(T_i)}\]맺음말
페이지랭크 알고리즘은 구글을 최고의 검색엔진의 자리에 올려놓은 알고리즘이다. 1995년 대학원생이던 그들이 인터넷과 세상을 크게 바꾸었다. 나는 어떤 서비스, 프로덕으로 세상을 바꿀 수 있을까? 그들의 알고리즘은 볼 때마다 새로운 자극을 주는 것 같다 😀