
Lucene Segment
ElasticSearch에서 샤드(Shard)를 구성하는 루씬(Lucene) Index와 역색인(Inverted Index) 구조와 문서 검색 기능의 구현체인 Lucene Segment에 대해 살펴보자. Lucene Segment를 이해했다면, ElasticSearch 동작의 핵심을 이해한 것이다!
ElasticSearch Index의 구조
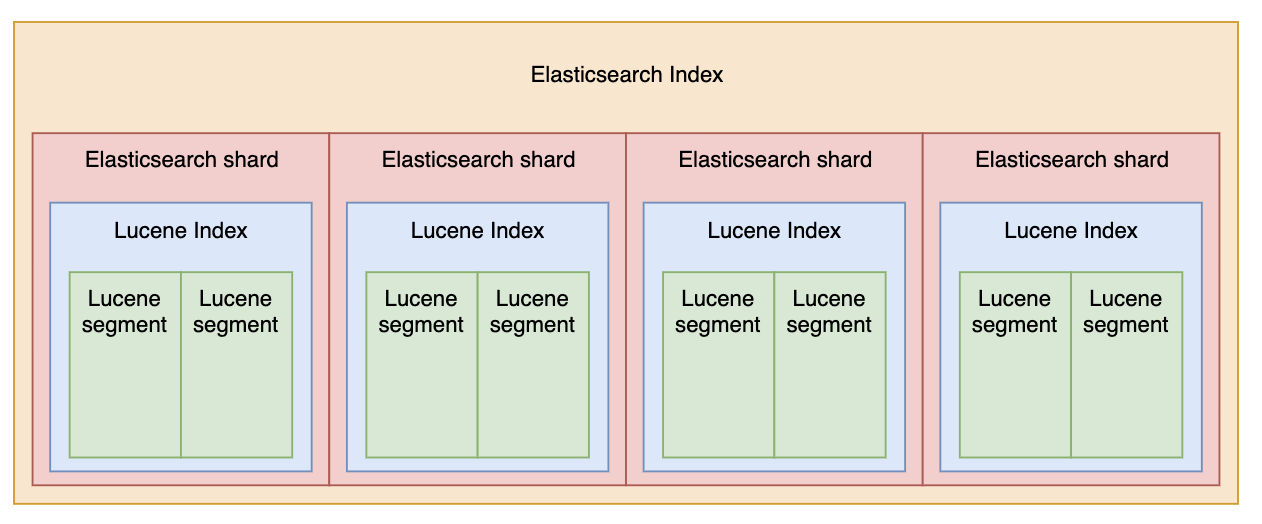
ElasticSearch Index는 여러 샤드(Shard)로 나눠진다. 샤드는 데이터를 나눈 일종의 파티션(Partition)이다.
하나의 ES 샤드는 하나의 Lucene Index를 가진다. 사실 ES 샤드는 Lucene Index를 확장한 것이나 다름 없다. 거의 비슷한 존재라고 보면 된다!
하나의 Lucene Index는 여러 Lucene Segment로 구성된다. 요 Lucene Segment 안에 ES Document와 역색인 구조가 존재하는 것이다.
Lucene Index와 Seegment
Lucene은 이상적인 준-실시간(Near-realtime) 검색 기능을 제공하기 위해 Lucene Index와 Lucene Segment 자료구조를 사용한다. Luncene Index와 Segment에서의 데이터를 검색/생성/석제/변경 로직을 살펴보자.
class LuSegment:
self.documents = [Document(1), Document(2), ...]
self.inverted_index = InvertedIndex()
class LuIndex:
self.segments = [Segment(1), Segment(2), ...]
문서 검색
Lucene Index의 검색은 인덱스가 가진 N개의 Lucene Segment에서 검색해서 그 결과를 조합한 것이다. 코드로 나타내면 아래와 같다.
class LuSegment:
self.documents = [Document(1), Document(2), ...]
self.inverted_index = InvertedIndex()
def search(self, qry: str):
doc_idx = inverted_index(qry)
return documents[doc_idx]
class LuIndex:
self.segments = [Segment(1), Segment(2), ...]
def search(self, qry: str):
qry_ret = []
for segment in segments:
ret = segment.search(qry)
qry_ret.append(ret)
return qry_ret
물론 위의 코드는 이해를 위해 Lucene Index와 Segment의 검색을 단순화 한 것이다.
각 Segment에서의 검색 결과를 취합하는 것도 단순히 .append() 하진 않을 것이다.
이렇게 Lucene Indexd에서 Segment 단위로 검색하고 검색 결과를 취합하는 방식을 “세그먼트 단위 검색(Per-Segment Search)”이라고 한다.
문서 생성
새로운 Document를 추가하면 Lucene Index는 새로운 Lucene Segment를 만들어 저장해둔다.
class LuSegment:
self.documents = [Document(1), Document(2), ...]
self.inverted_index = InvertedIndex()
def __init__(self, document: Document):
self.documents = [document]
self.inverted_index = InvertedIndex(document)
class LuIndex:
self.segments = [Segment(1), Segment(2), ...]
def insert(self, document: Document):
newSegment = Segment(document)
self.segments.append(newSegment)
그러나 Document를 추가로 세그먼트가 생성되기만 한다면 Segment는 늘 하나의 Document만 가지게 된다. 그래서 Lucene Index는 주기적으로 “Merge” 작업을 통해 Segment를 병합한다.
class LuSegment:
self.documents = [Document(1), Document(2), ...]
self.inverted_index = InvertedIndex()
def __init__(self, seg1: Segment, seg2: Segment):
self.documents = seg1.documents + seg2.documents
self.inverted_index = InvertedIndex(self.documents)
class LuIndex:
self.segments = [Segment(1), Segment(2), ...]
def merge(self):
seg1 = segments[0]
seg2 = segments[1]
newSegment = Segment(seg1, seg2)
segments.push(newSegment)
del seg[0:2]
Lucene Index의 Segment 둘을 골라 새로운 Segment를 생성한다. 두 Segment가 합치면, 검색에서 Lucene Index가 탐색할 Segment 수가 줄어든다!
물론 위의 코드는 이해를 위해 Merge 작업은 단순화 한 것이다! 실제론 병합할 두 Segment를 선택하는 방식도 복잡하며, Merge 과정 중에는 삭제 표시된 문서의 “물리적 삭제”도 이뤄진다!
문서 삭제
Lucene Index에서 Document와 Lucene Segment는 불변성(immutability)를 가진다. 이것은 문서에 대한 삭제 요청이 발생해도 해당 Document를 실제로 물리적 공간에서 삭제하지는 않는다는 말이다! 다만, 유저(Client) 입장에선 문서가 삭제되었다는 응답은 정상적으로 받는다.
대신 삭제 요청 온 문서의 id를 검색해서 해당 id를 가진 문서들에 "삭제됨"라는 표시만 해둔다. 그럼 물리적 삭제는 언제 일어나는가? 물리적 삭제는 Segment가 “머지”될 때, Segment의 문서 중에 "삭제됨" 표시가 있는 문서를 삭제하는 것이다.
class LuSegment:
self.documents = [Document(1), Document(2), ...]
self.inverted_index = InvertedIndex()
def delete(self, doc_id: str):
doc_idx = self.inverted_index(id)
doc = self.documents[doc_idx]
doc.is_deleted = True
def __init__(self, seg1: Segment, seg2: Segment):
self.documents = []
for document in (seg1.documents + seg2.documents):
if document.is_delete:
continue
self.documents.append(document)
self.inverted_index = InvertedIndex(self.documents)
class LuIndex:
self.segments = [Segment(1), Segment(2), ...]
def delete(self, doc_id: str):
for segment in segments:
segment.delete(doc_id)
def merge(self):
...
문서 변경
ES에서 문서의 변경은 DB에서의 변경과 달리 Overwrite(Delete & Write)가 아닌 새로 Document를 만든 후 문서의 “버전”을 올리는 것이다. 즉, Mark Delete를 한 후 Write를 하는 셈이다! 그래서 문서를 변경하는 것은 사실 Lucene Index에서 문서를 삭제하고 새로 문서를 하나 생성하는 것과 같다! 단, 여기서의 문서 삭제는 물리적 삭제가 아니라 Mark Delete 하는 것을 말한다.
class LuIndex:
self.segments = [Segment(1), Segment(2), ...]
def update(self, doc_id: str, document: Document):
self.delete(doc_id)
self.insert(doc_id, document)
세그먼트 불변성
왜 Lucene은 세그먼트 불변성(Segment Immutability)를 채택한 것일까?
먼저 세그먼트 불변성이 없는 상황에서 문서를 삭제 한다고 생각해보자. 그러면 Segment의 (1) 문서 리스트에서 문서를 삭제하고 (2) Inverted Index를 갱신하는 두 과정을 다시 수행해줘야 한다.
그런데 Segment가 수정 하는 중인데, 해당 Segment에 검색 요청이 오는 경우를 생각해보자. 그러면 검색 작업 입장에서는 2가지 선택지가 있는데
- 수정 중인 Segment는 스킵한다.
- Segment 수정이 끝날 때까지 기다린다.
1번 방식을 채택하면, 수정 중인 Segment에 있는 Document가 검색 결과에서 스킵 되기 때문에 검색 결과가 부정확 해진다. 2번 방식을 채택하면, 문서 삭제 요청 이후에 트리거된 모든 검색이 Segment 수정이 완료될 때까지 pending 되어버린다!
결국, Segment를 수정하는 작업 자체가 검색 엔진에게는 부담스러운 작업이라는 말이다!
결국 Lucene은 세그먼트 내의 문서에 변경/삭제 작업이 일어나면 일단 가지고 있는 문서를 "삭제됨"으로 표시해두고, 새로운 버전의 문서가 담긴 Segment를 생성하게 된 것이다!