
Swarmpit 클러스터 장애 회고
Docker swarm 클러스터를 운영하면서 겪었던 장애 사례들을 모아 간략히 회고 하고자 한다.
dangling 인한 워커 노드 용량 부족 문제
Dangling image란 더이상 사용하지 않는 도커 이미지를 말한다. 도커 스웜에는 “Auto Deploy” 옵션이 있기 때문에 이미지가 업데이트 되면 ECR에서 새로운 이미지를 pull 받고 기존 이미지는 dangling 이미지가 된다.
“Auto Deploy” 기능 덕분에 DevOps의 CD를 구축하게 되면서 나는 신나게 코드를 개발해서 Dev 환경에도 올리고 Prod 환경에도 올리고 있었다. 그런데…
어느날 갑자기 Auto Deploy 되는 서비스에서 이미지를 못 읽어오는 사태가 벌어졌다.
- Github Action으로 빌드 & 푸시도 성공했고
- AWS ECR에도 잘 있고
- 로컬에서도
docker pull이 잘 되는데…
이상하게도 워커 노드에서만 docker pull이 안 되는 현상이 벌어졌다!
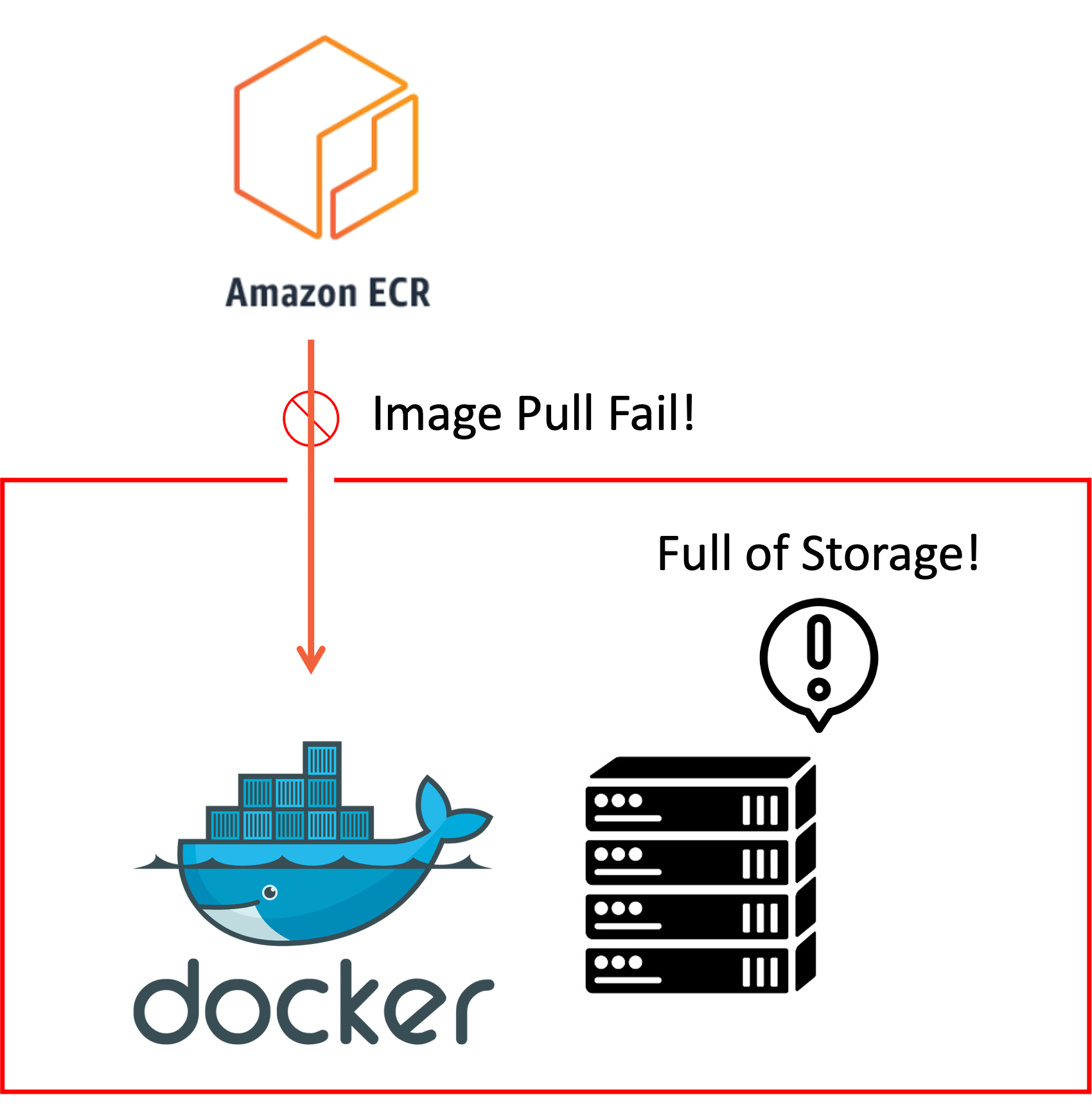
요리조리 살펴보니 워커 노드에서 dangling 이미지가 너-무 많이 쌓여서 워커 노드의 스토리지 사용량이 “100%”가 되어버린 것이다!
그길로 워커 노드에 접속해서 docker image prune을 갈겨 줬더니 스토리지 용량이 풀리면서 Swarm 클러스터가 정상 동작하기 시작했다!
K8s는 이걸 어떻게 해결하고 있는가
마찬가지로 컨테이너 오케스트레이션 플랫폼인 K8s는 이 문제를 어떻게 해결하는 걸까?
K8s에서도 Pod에서 사용하고 난 이미지는 dangling 이미지가 되어 워커 노드에 존재하게 된다. K8s에서는 “Garbage Collection“라는 이름으로 클러스터 리소스를 정리하고 있었다. 이제부터는 줄여서 “GC”라고 편하게 부르겠다.
K8s GC는 아래의 작업들을 수행하며 클러스터 리소스를 정리한다.
- Terminated Pods
- Completed Jobs
- “Unused Containers and Container Images”
- 등등…
K8s Image GC
K8s의 kubelet은 주기적으로 아래 작업을 수행한다.
- 5분 마다 dangling 이미지를 삭제
- 1분 마다 unused 컨테이너를 삭제

그렇다고 image GC 과정이 5분 마다 모든 dangling image를 삭제하는 것은 아닌데, kubelet의 옵션인 imageGCHighThresholdPercent와 imageGCLowThresholdPercent를 기준으로 image GC를 수행한다.
워커 노드의 스토리지 사용량이 기본값이 “85”인 imageGCHighThresholdPercent를 넘기면 kubelet이 image GC를 수행한다. 이때, 사용 시점을 기준으로 정렬해서 옛날에 사용된 이미지들을 지운다. 단, 모든 이미지를 지우는 것은 아니며 스토리지 사용량이 imageGCLowThresholdPercent가 정도로만 image GC를 수행한다. imageGCLowThresholdPercent의 기본값은 “80”이다.
로컬 로깅 활성화 및 Max-Age
초기엔 logging으로 인한 리소스 소모를 막으려고 logging 옵션을 꺼뒀다.
services:
service_name:
logging:
driver: None
이렇게 하면 컨테이너의 로그를 전혀 볼 수 없다.
$ docker logs <container-id>
Error response from daemon: configured logging driver does not support reading
그러나 Swarm 클러스터를 운영하면서 컨테이너의 로그를 보고 디버그 해야 하는 상황이 종종 있었고, 아래와 같이 logging 옵션을 부여했다.
services:
service_name:
logging:
driver: local
options:
max-size: 15m

로그를 15분 정도 유지하는 건 전혀 부담되지 않을 것 같았다. 게다가 요 옵션을 켜면, 워커 노드에서 귀찮게 docker logs로 확인할 필요 없이 Swarmpit 웹에서 바로 로그를 확인할 수 있다!
Deploy RollBack 옵션 추가
Docker Service의 처음 설정되어 있던 Deploy 옵션은 아래 사진과 같다.
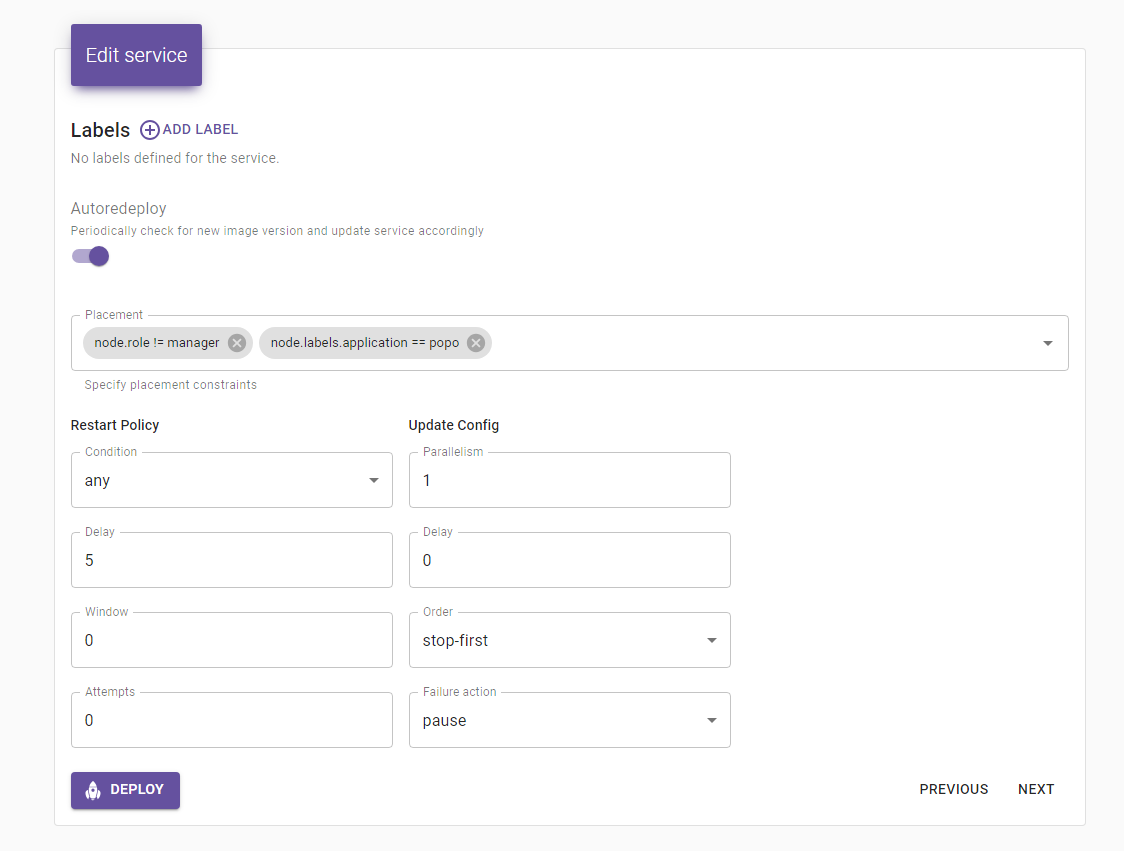
그런데 이렇게 설정하니 종종 있는 Deploy Fail에서 서비스가 아예 죽어버리는 문제가 있었다. 그래서 옵션을 아래와 같이 조정해 Rollback 할 수 있도록 변경했다.
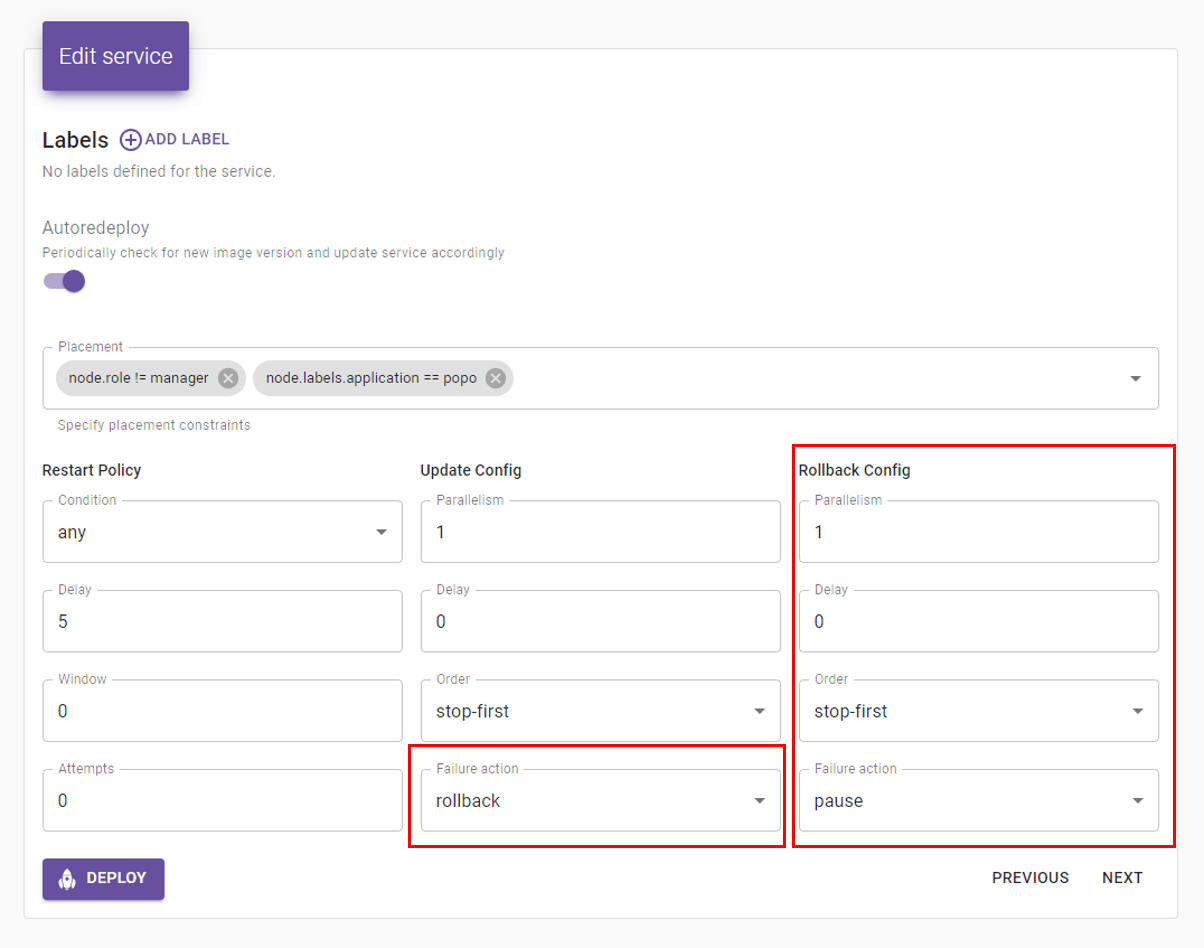
요 작업을 진행하면서 Docker Swarm의 Update/Rollback 옵션의 의미를 살펴봤는데, 아래와 같다.
- Parallelism
- Update/Rollback을 진행할 ‘레플리카’ 갯수
- 많은 수의 레플리카가 있어 한번에 2개 이상의 Update/Rollback이 필요하다가 2 이상의 값을 주면 좋을 것이다.
- Delay
- Update/Rollback 후, 다음 ‘레플리카’에 Update/Rollback을 적용하기 까지의 Delay
- Monitor
- Update/Rollback 후, 신규 컨테이너가 “Running”인지 “Fail”인지 모니터링하는 기간
- Order
- “start-first”: 신규 컨테이너를 띄울 수 있는 노드에 먼저 띄워서 확인 후에, 기존 컨테이너 삭제
- 단, 신규 컨테이너를 띄울 노드가 없다면, “stop-first” 방식을 채택하는 것으로 보인다.
- “stop-first”: 기존 컨테이너 종료 후에 신규 컨테이너 띄움
- “start-first”: 신규 컨테이너를 띄울 수 있는 노드에 먼저 띄워서 확인 후에, 기존 컨테이너 삭제
더 자세한 내용은 Docker Swarm의 공식 문서: “docker service update“에서 확인하자.