
2023 AWS re:invent 신기술 정리

회사에서 AWS re:invent를 보내준 덕분에 처음으로 미국도 다녀오고, 전세계 개발자가 모인 현장을 경험할 수 있었다 ㅎㅎ re:invent를 그냥 놀러만 간 건 아라서 AWS re:invent에서 소개된 신기술과 신기능들을 정리해보겠다!

아, 그런데 이번 AWS re:invent 2023에서 소개된 기술 말고도, 예전에 출시/소개 되었는데 이번에 자료 정리하면서 본인이 새로 알게된 서비스도 같이 적었다!
EKS 관련
EKS의 prometheus 지표를 에이전트 없이 수집
https://docs.aws.amazon.com/ko_kr/eks/latest/userguide/prometheus.html
EKS로 운영하는 k8s 클러스터의 Prometheus 지표를 prometheus agent 설치 없이 EKS 콘솔과 API 호출을 통해서 Prometheus 지표 정보를 수집할 수 있다!
EKS 클러스터를 생성할 때, Prometheus 지표를 내보내게 할 수 있다.
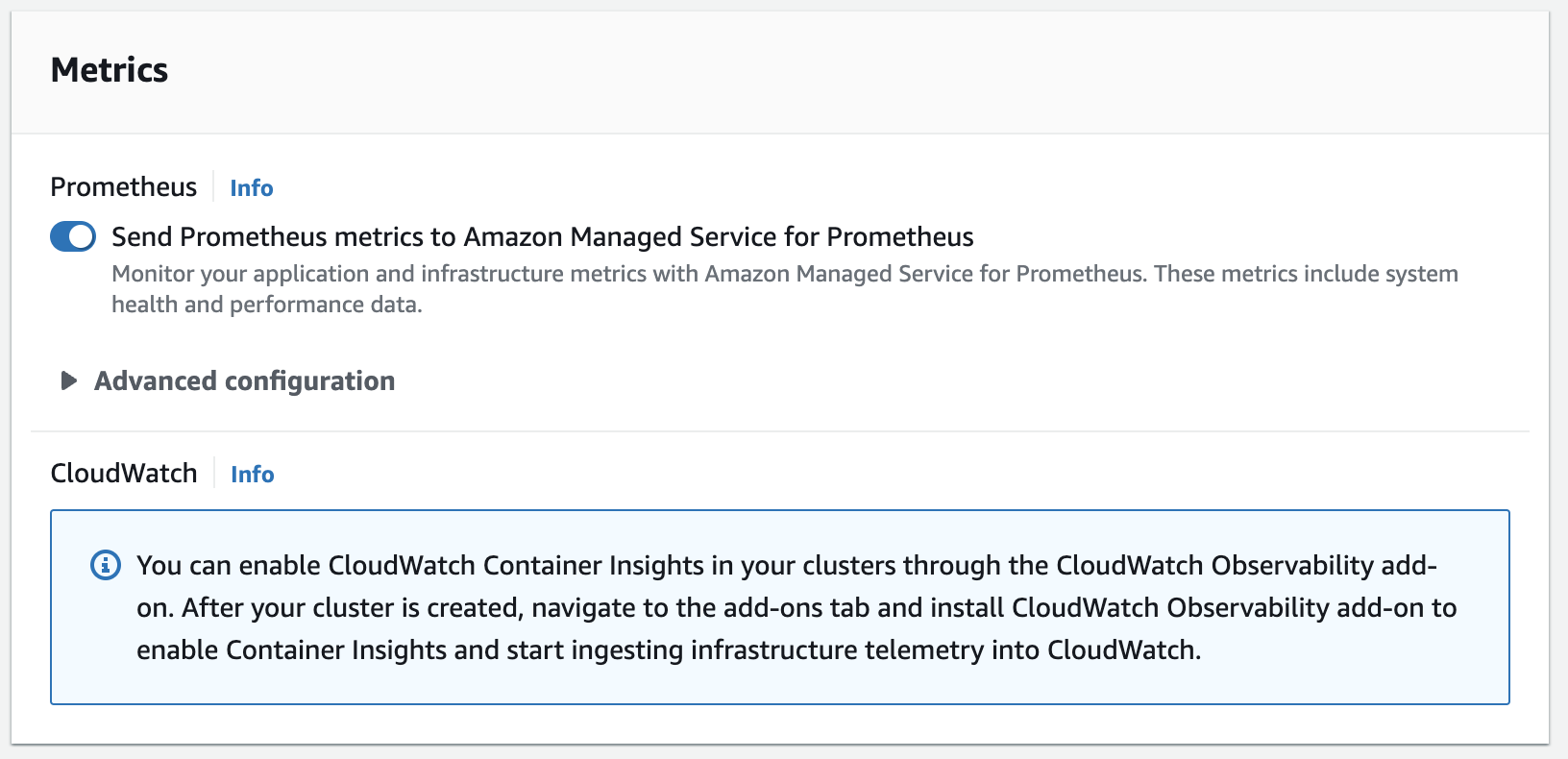
단, 단점은 이 Prometheus 지표를 Amazon Prometheus로만 export 할 수 있는 것 같다.
또, 기존에 이미 생성된 EKS 클러스터에서는 요 기능을 활성화 하는 방법을 못 찾았다 😢
Amazon Prometheus & Grafana
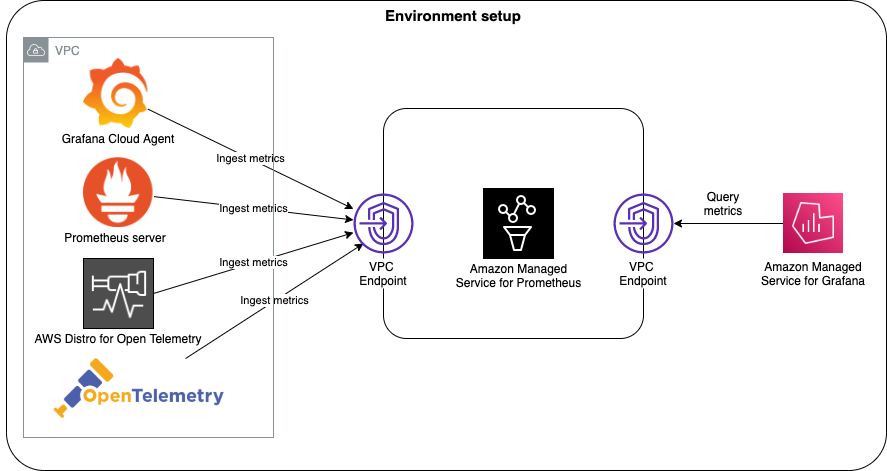 https://aws.amazon.com/blogs/mt/getting-started-amazon-managed-service-for-prometheus/
https://aws.amazon.com/blogs/mt/getting-started-amazon-managed-service-for-prometheus/
AWS에서 서비스하는 managed Prometheus와 Grafana.
현재는 eks 클러스터 마다 prometheus를 띄워서 지표를 보고 있는데, 클러스터 독립적인 하나의 prometheus만을 띄워서 프메 지표를 수집하는 용도로 쓸 수 있지 않을까?
AWS IRSA(IAM Roles for Service Account)
https://docs.aws.amazon.com/eks/latest/userguide/iam-roles-for-service-accounts.html
현재 우리 팀의 EKS 클러스터가 채택하고 있는 방식이다. 과거 Kops+Kiam 조합으로 사용하던 방식에서 요 방식으로 넘어왔다고 한다.
EKS에 부여된 OIDC(Open ID Connect)와 AWS STS를 이용해 Pod에 IAM Role을 부여하는 방식이다.
kind: ServiceAccount
annotations:
eks.amazonaws.com/role-arn: arn:aws:iam::280144880143:role/ExternalSecretsRole
본래 K8s ServiceAccount은 K8s Pod이 K8s 클러스터 API에 대한 권한을 정의하는 용도로 사용되는데, IRSA에선 ServiceAccount를 사용해 K8s Pod에 AWS IAM 권한을 부여한다!
K8s Pod이 SA를 이용해 IAM Role의 권한을 획득하는 과정은 아래와 같다.

출처: https://aws.amazon.com/blogs/containers/diving-into-iam-roles-for-service-accounts/
- K8s Pod에 K8s SA를 biding 한다.
- 이때, k8s Pod은 SA에 담긴 정보를 JWT 토큰으로 mount 받아 가지고 있게 된다.
- K8s Pod에서 AWS SDK로 특정 AWS 연산을 수행하려고 한다.
- Pod의 AWS SDK에서 JWT와 IAM Role 정보를 AWS STS에 넘긴다.
- STS는 IAM에게 임시 자격증명을 줄 수 있는지 IAM에 확인을 요청한다.
- IAM은 IAM OIDC Provider(EKS OIDC)와 통신해 Pod이 사용하려고 하는 ServiceAccount 정보가 정말로 Pod에 바인딩 되어 있는지 체크한다.
- IAM이 STS에게 임시 자격증명을 줘도 된다고 응답한다.
- STS는 Pod의 SDK에게 임시 자격증명을 전달한다.
참고자료
EKS pod identity
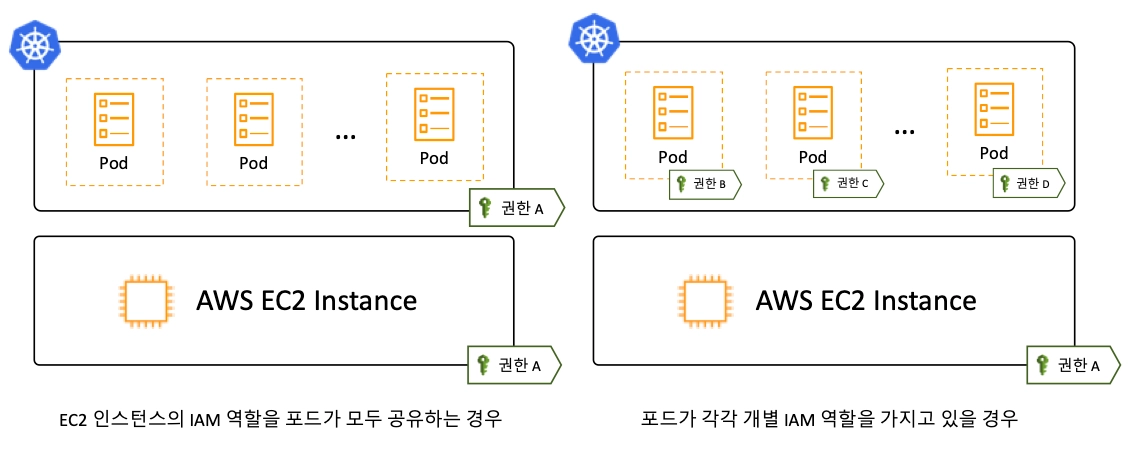
출처: Devsisters 기술블로그
https://aws.amazon.com/ko/about-aws/whats-new/2023/11/amazon-eks-pod-identity/
EKS에서 각 Pod에 특정 IAM Role을 할당 하는 방법은 Kiam과 AWS IRSA(IAM Roles for Service Account) 등 여러 가지가 있는데, 이젠 이걸 EKS 전용으로 디자인된 기능을 제공한다!!
그런데 IRSA로 충분할 것 같은데, 왜 이게 출시된 걸까?
IRSA의 단점.
https://aws.amazon.com/blogs/containers/amazon-eks-pod-identity-a-new-way-for-applications-on-eks-to-obtain-iam-credentials/
- IRSA는 ServiceAccount가 사용하려는 IAM Role에서 해당 EKS 클러스터의 OIDC provider 정보를 Trusted Relationship에 추가해줘야 한다.
- IRSA는 처음에 EKS에 대한 OIDC provider를 만들어 줘야 하는데, 이걸 만드려면 EKS admin 권한이 필요하다. 그리고 EKS cluster 마다 OIDC provider 만드는게 번거롭다 등등
그럼 Pod Identity는 어떤가?

출처: AWS Blog: Amazon EKS Pod Identity: a new way for applications on EKS to obtain IAM credentials
- OIDC provider 셋업 없이 pod에 IAM role 부여 가능.
- AWS STS 거치지 않고, EKS 전용 Pod Identity API 통해서 AssumeRole 수행
- 또, EKS에서 사용하려는 IAM Role의 Trust Relationship 수정도 필요 없음.
- ServiceAccount에 붙이던
annotations도 필요 없다!

단, 요 Pod Identity 기능을 사용하려면 “Amazon EKS Pod Identity Agent”라는 EKS addon을 설치해야 한다. 그리고 Trust Relationship을 적는 것 대신 EKS 콘솔 또는 AWS CLI 통해서 해당 ServiceAccount에 IAM Role을 바인딩 해주면 된다!
 https://aws.amazon.com/blogs/containers/amazon-eks-pod-identity-a-new-way-for-applications-on-eks-to-obtain-iam-credentials/
https://aws.amazon.com/blogs/containers/amazon-eks-pod-identity-a-new-way-for-applications-on-eks-to-obtain-iam-credentials/
기존 AWS IAM에 Trust Relationship을 적는 것과, K8s ServiceAccount의 annotations에 적던 방식은 Pod Identity Association을 맺는 방식으로 변경 되었습니다!
EMR on EKS
https://docs.aws.amazon.com/emr/latest/EMR-on-EKS-DevelopmentGuide/emr-eks.html
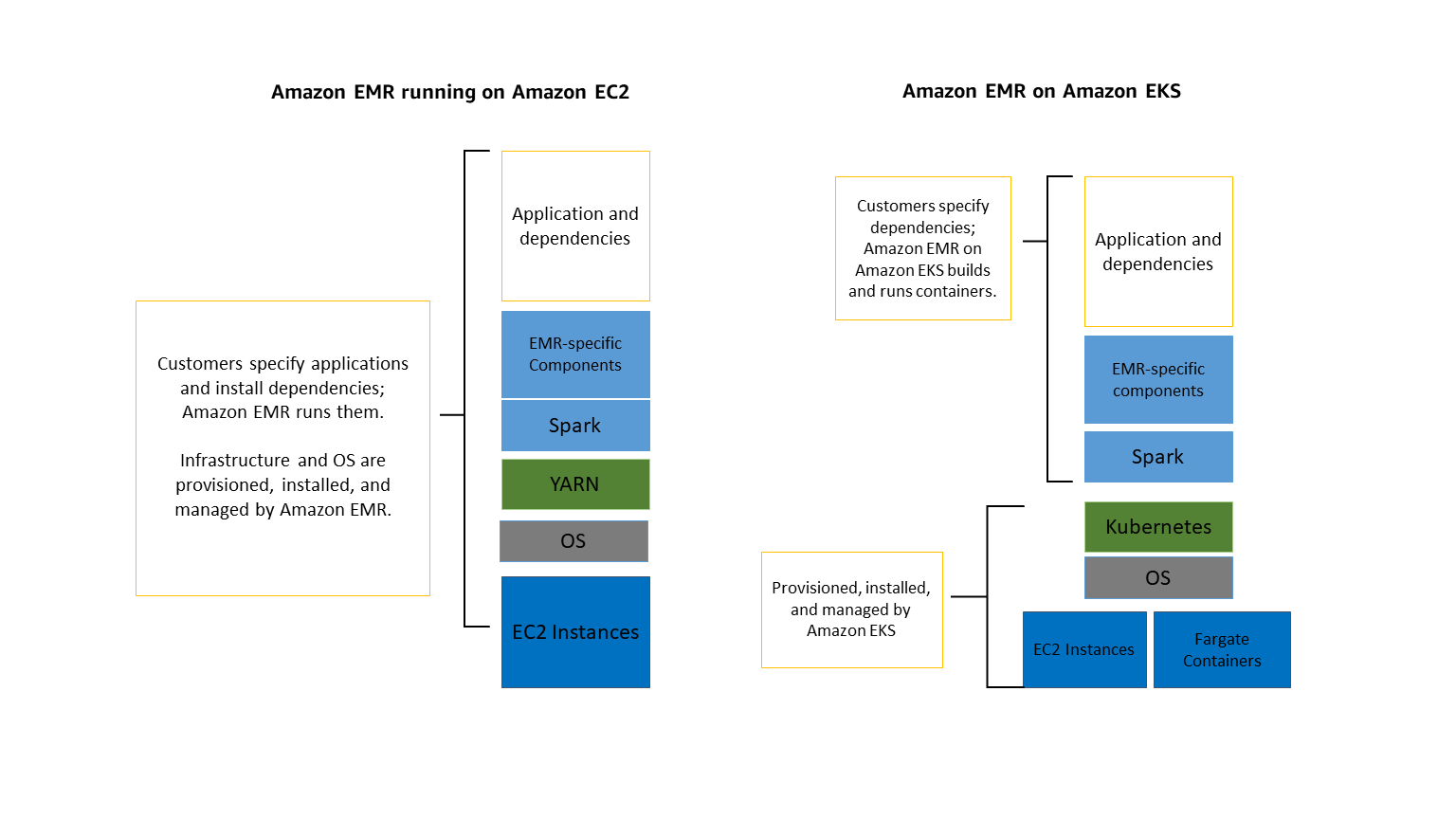
EMR을 그냥 돌리면, ec2 instance의 묶음을 분산 노드로 사용함. 그런데, EKS 위에서 EMR들 돌리게 되면, provisioned ec2 노드를 사용할 수도 있고, EKS Fargate를 조합해서 좀더 탄력적으로 운영할 수도 있음.
추가로 EKS 위에 EMR application 외에 다른 K8s app을 함께 운영할 수도 있음!
기존 ec2 기반의 EMR의 단점 때문에 “spark-on-kubernetes”를 도입했다면, EMR on EKS가 도움이 될 지도! 뱅크샐러드는 EMR on ec2를 사용하다가 spark-on-kubernetes로 이전 했다.
EC2 관련
Nitro System
https://aws.amazon.com/ko/ec2/nitro/
2017년 발표된 AWS EC2에 적용된 좀더 발전된 가상화 기술.
nitro 시스템 도입으로 인해 EC2는
- CPU, 메모리, Network를 커스텀한 더 다양한 인스턴스 타입을 지원
- 경량화된 가상화 방식으로 “베어 메탈”과 거의 차이 없는 성공 제공
nitro system은 c5, m5, r5 등 5세대 인스턴스부터 적용됨. 그래서 c5d 인스턴스는 c4 인스턴스보다 25~50% 개선된 성능을 제공함.
Gaviton4 기반 EC2 r8g 인스턴스 출시
https://aws.amazon.com/ko/blogs/korea/join-the-preview-for-new-memory-optimized-aws-graviton4-powered-amazon-ec2-instances-r8g/
Gaviton 프로세스 제품군 중 가장 최신 세대.
Graviton3를 기반으로 하는 7세대(r7g)에 비해 8세대는 최대 3배의 vCPU, 3배의 메모리 용량. 최대 30% 향상된 컴퓨팅 성능을 제공.
S3 관련
S3 Express One Zone 스토리지 클래스
https://aws.amazon.com/s3/storage-classes/express-one-zone/
데이터를 특정 region의 한 AZ에 저장함. 그래서 S3 Standard에 비해 엑세스 속도가 10배 향상, 요청 비용이 50% 감소 한다고 함.
단점은 One AZ이기 때문에 해당 AZ의 데이터센터 화재/수해 등의 사고 발생 시 데이터 유실됨. 또, 10x 속도를 보장하기 위해선 해당 one zone S3에 접근하는 compute 역시 같은 AZ 위에 띄워야 함.
PyTorch 용 S3 커넥터
https://aws.amazon.com/ko/about-aws/whats-new/2023/11/amazon-s3-connector-pytorch/
소스코드: https://github.com/awslabs/s3-connector-for-pytorch
Pytorch가 S3에 있는 훈련 데이터와, S3에 있는 체크포인트 R/W를 좀더 빠르게 가능하게 함. 해당 S3 connector 내부적으로 Read/List 작업을 최적화 한다고 함.
찾아봤는데 Tensorflow, Keras에 대한 S3 커넥터는 아직 없는 것 같음.
아래는 예시코드
from s3torchconnector import S3Checkpoint
import torchvision
import torch
CHECKPOINT_URI="s3://<BUCKET>/<KEY>/"
checkpoint = S3Checkpoint(region="us-east-1")
model = torchvision.models.resnet18()
# Save checkpoint to S3
with checkpoint.writer(CHECKPOINT_URI + "epoch0.ckpt") as writer:
torch.save(model.state_dict(), writer)
# Load checkpoint from S3
with checkpoint.reader(CHECKPOINT_URI + "epoch0.ckpt") as reader:
state_dict = torch.load(reader)
model.load_state_dict(state_dict)
S3 Batch Operation
https://aws.amazon.com/about-aws/whats-new/2023/11/amazon-s3-batch-operations-buckets-prefixes-single-step/
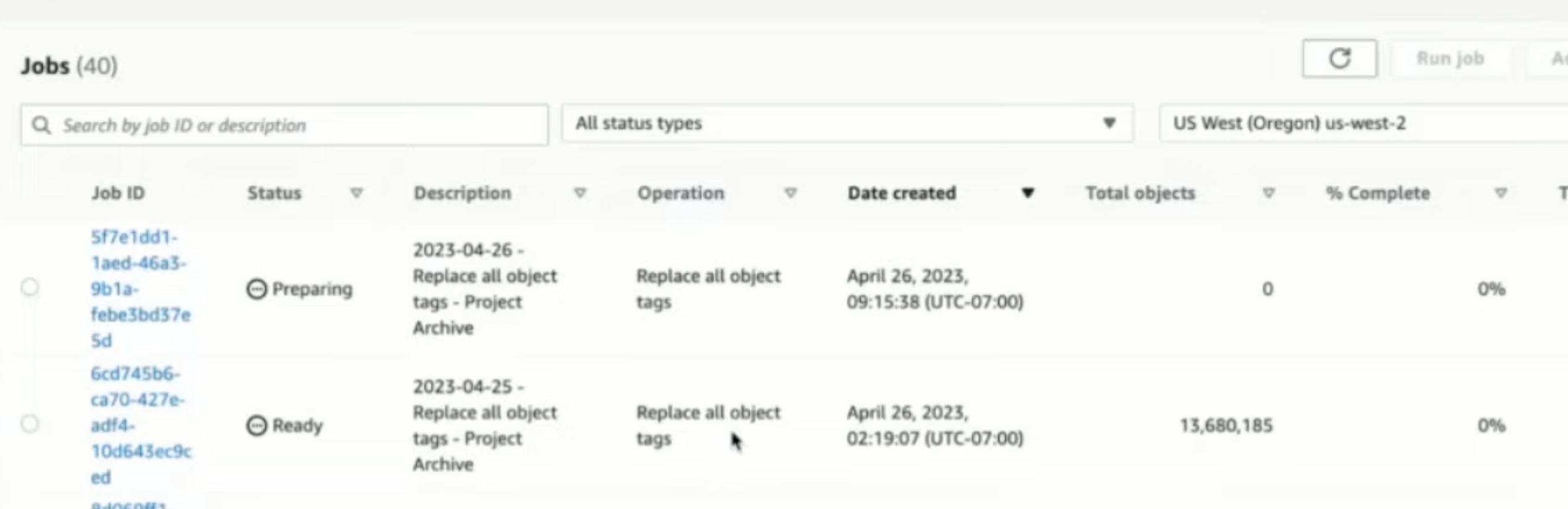
출처: AWS Document: Creating an S3 Batch Operations job
S3 버킷에 전체 obj, prefix, suffix 조건으로 작업을 수행하는 job을 추가할 수 있게 됨. 해당 job 기능의 이름이 “Batch Operation”임.
쉽게 말해서 S3 콘솔에서 configuration, 진행 정도를 확인할 수 있는 AWS S3 CLI를 수행하는 거라고 볼 수 있음.
사용 예시는, 조건에 맞는 obj들을
- 다른 bucket으로 copying
- lambda function으로 보내기
- tag 변경하기
등등이 있다.
데이터 관련
zero-ETL
ETL 데이터 파이프라인을 구축하지 않거나 최소 정도로 구축하는 접근법. ETL 파이프라인은 데이터를 가공 하는 과정에서 데이터 이동이 빈번히 발생하는데, 이런 데이터 이동을 최소화 한 것이 zero ETL임.
예시)
- S3에서 redshift로 자동 복사: s3에 새 파일이 만들어지는 즉시 데이터를 redshift에 로딩
- AWS RDS의 데이터를 Redshift로 실시간으로 싱크
Opensearch zero-ETL integration with AWS S3
https://aws.amazon.com/about-aws/whats-new/2023/11/amazon-opensearch-zero-etl-integration-s3-preview/
OCU(OpenSearch Computing Unit) 이용한 S3 서버리스 Ingestion 지원.
지금은 logstash로 kafka topic에서 OpenSearch로 데이터를 연동하는데, S3에서 바로 연동 해도 될 듯.
DynamoDB zero-ETL integration with Redshift
https://aws.amazon.com/about-aws/whats-new/2023/11/amazon-dynamodb-zero-etl-integration-redshift/
Redshift에서 DynamoDB 데이터에 대해 고성능 분석을 실행 가능.
DynamoDB의 프로덕션 워크로드에는 영향 x
Serverless ElasticCache 지원
https://aws.amazon.com/blogs/aws/amazon-elasticache-serverless-for-redis-and-memcached-now-generally-available/
드디어 ElasticCache에도 Serverless 컴퓨팅을 지원합니다!
Redshift의 External Table에 Apache Iceberg 지원
https://docs.aws.amazon.com/redshift/latest/dg/querying-iceberg.html
Q. Redshift External Table이란?
A. Redshift 데이터베이스 내에 저장되는 테이블이 아니라 데이터가 외부(S3, Glue)에 저장된 경우를 말함.
External Table에선 .csv, .parquet format을 지원하고, Apache Hudi, Delta Lake 포맷도 이미 지원하고 있었음.
https://docs.aws.amazon.com/redshift/latest/dg/c-spectrum-external-tables.html
그런데 이번에 Apache Iceberg 포맷도 지원하게 된 것!
Apache Iceberg
Apache Hive에서 대규모 데이터를 다룰 때 발생하는 문제를 해결하기 위한 새로운 데이터 저장 방식으로 Netflix가 처음 개발해 공개 했다.
원래 Hive에선 아래와 같은 여러 한계가 있다.
- 완벽하게 지원되지 않는 ACID
- Transaction으로 Update 요청이 올 때 완벽하게 처리되지 않는다.
- 스키마 확장성 미지원
- Hive는 메타데이터를 hive metadata store에 관리함.
- 그래서 파티션이나 스키마 정보를 업데이트 하려면 해당 테이블을
DROP하고 다시 생성 해야 함.
- Latency 개선을 위해 테이블 compaction시 테이블을 일시적으로 사용 불가
이런 Hive의 문제를 해결하기 위해 몇몇 새로운 데이터 저장 방식이 파생 되었는데, Uber에서 만든 Hudi, Netflix에서 만든 Iceberg, Databricks에서 만든 Delta Lake가 있다.
그래서 Iceberg랑 Delta Lake는 같은 문제를 해결하기 위해 개발된 프레임워크이기 때문에 장점도 비슷하다.
- ACID Transaction 지원
- 동시성 제공: 데이터 변경 되는 중에 읽기 가능
- 테이블 메타데이터 확장 가능
- Delta Lake는 이 부분을 더 확장해서 Unity Catalog로 진화 했다.
- Snapshot 방식이기 때문에 Time Travel과 Rollback 기능 지원
국내에선 LINE이 Data Platform으로 Apache Iceberg를 채택.
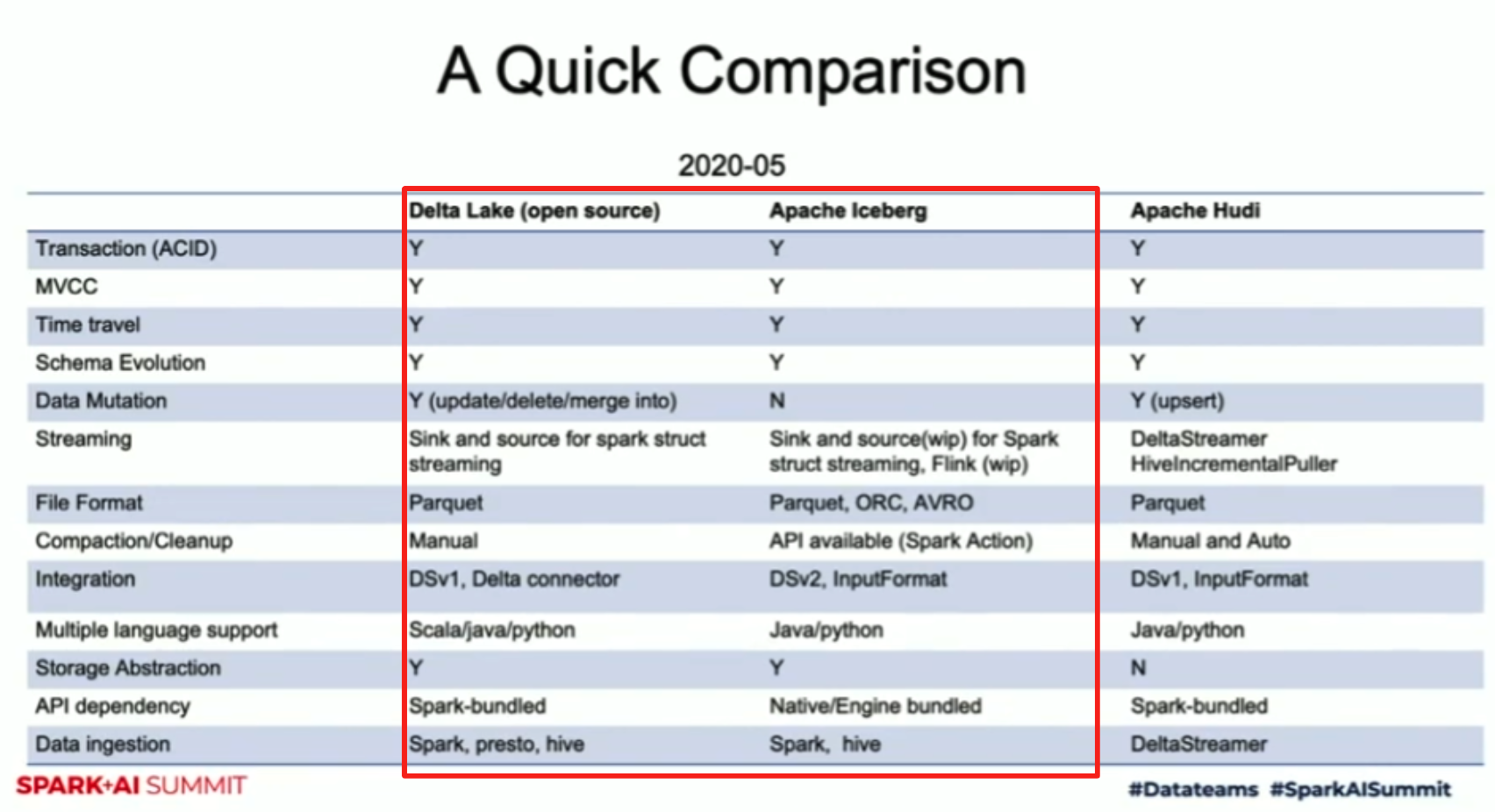
출처: https://www.youtube.com/watch?v=Wx8G08jaedo
Vector Search

출처: https://learn.microsoft.com/ko-kr/azure/search/vector-search-overview
텍스트, 이미지 등 비정형 데이터의 의미와 컨텍스트를 있는 그대로가 아닌 embedding된 숫자 표현으로 변환해 저장하고, 검색 역시 검색어를 embedding된 숫자 표현으로 변환해 두 embedding 사이의 유사도로 검색을 수행하는 방법.
Vector Search for MemoryDB for Redis
벡터 검색을 AWS MemoryDB for Redis에서 쓸 수 있게 되었다고 한다.
Vector Engine for OpenSearch Serverless
AWS OSS에 Vector Engine이 추가되어 Vector Storage/Search가 가능하다고 한다.
Vector Search for DocumentDB/DynamoDB
그렇다고 한다.
AI 관련
이번 2023 re:invent 때는 Bedrock 관련 신규 내용이 정말 많았다!! 정말 LLM이 유행이긴 유행인 듯…
Amazon Titan
https://aws.amazon.com/ko/bedrock/titan/
AWS에서 개발한 LLM 파운데이션 모델(FM).
모든 Titan FM은 데이터에서 유해 콘텐츠를 감지함. 사용자의 부적절한 입력을 거부하고 모델 출력을 필터링 함.
- Titan Text Express ✨
- Titan Text Lite ✨
- 요약, 카피라이팅 전용
- Titan Text Embeddings
- Text -> 1536 size embedding
- Titan Multimodal Embeddings ✨
- Text+Image -> embedding
- Titan Image Generator ✨
- Titan으로 만든 Image에는 기본적으로 워터마크가 포함됨
Amazon Bedrock
https://aws.amazon.com/ko/bedrock/
각종 AI 회사의 고성능 FM 모델과 생성형 AI 앱을 구축하는데 필요한 기능들을 제공하는 서비스.
주요 지원 FM
- Amazon Titan 시리즈
- Meta Llama 2 ✨
- Anthropic Claude 2.1 ✨
- Stable Diffusion
- 등등
Amazon Trascribe
AWS에서 제공하는 Audio to Text 서비스.
100+개 언어를 자동으로 인식. 문화권과 악센트별 음성 데이터를 학습 했다고 함.
AWS Personalize: Next Best Action
사용자가 취할 가능성이 높은 작업을 실시간으로 추천하는 레시피가 추가됨
현재 Personalize에서 제공하는 레시피로는
- User Personalization
- Popular Items
- Personalize Ranking
- Related Items
- Personalize Actions
- Next Best Action ✨
- User Segmentation
그외
AWS console-to-code
https://aws.amazon.com/about-aws/whats-new/2023/11/aws-console-to-code-preview-generate-console-actions/
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/console-to-code.html
웹콘솔에서 수행된 작업을 선택한 언어로 쉽게 변환 가능.
현재는 us-east-1 리전에서만 EC2에 대한 웹콘솔 작업만 console-to-code 변환이 가능하다고 함.
AWS Kuiper
https://www.aboutamazon.com/news/innovation-at-amazon/amazon-project-kuiper-aws

AWS의 위성 프로젝트.
기지국과 광케이블이 깔리지 않은 도서 지역, 수도/전기가 도달하지 못 하는 지역까지 인터넷을 가능하게 하려는 AWS의 프로젝트.
최종 목표는 극지방을 제외하고 사람이 사는 거의 모든 지역에 인터넷이 가능하도록 만드는 것.
Amazon Q
웹 콘솔에서 쓸 수 있는 대화형 assistant.
써보니까 AWS 관련 질문은 답변을 잘 하고 있음.
https://apps.apple.com/us/app/aws-console/id580990573
AWS 모바일 Console에서도 Amazon Q 사용 가능!
Code Catalyst
https://codecatalyst.aws/explore
AWS에서 제공하는 Git SVM 서비스.
Github, GitLab과 유사한 서비스를 AWS에서 제공하겠다는 것.
PR, Issue, CI/CD 같은 기능들이 모두 들어 있고, AWS Code 시리즈(CodeCommit, CodeBuild, CodeDeploy, CodePipeline)과 좀더 궁합이 좋다고 함.

AmazonQ와 통합해 개발 요구조건을 명시하면, 그걸 기반으로 거의 완성본인 형태의 PR을 만들어 주는 기능도 있다고 함.
나의 첫 미국 방문이었는데, 회사에서 좋은 사람들과 대표님과 함께 다녀와서 진짜 너무 편하고 또 재밌게 다녀왔다!! ㅎㅎ 가서 맛있는 것도 정말 많이 먹었는데, 맛집들을 네이버 블로그에 한번 정리해봤다 🎰 라스베가스 여행기: 맛집 탐방 🤤
회사의 팀 블로그에서 한번 적어봤다 ㅎㅎ Bagelcode: 2023 AWS re:invent 신기술 정리
참고자료
- 요기요 기술블로그: 2023 AWS re:invent 후기
- 2023 AWS re:invent 직접 가서 듣고 온 키노트 🤓
- 그외 AWS 기술블로그와 가이드 문서