
Delta Lake Optimize
회사에서 Databricks를 통해 Spark Cluster를 운영하고 있습니다. 본 글은 Databricks를 기준으로 작성했음을 미리 밝힙니다.
Compaction
Parquet 테이블의 쿼리 시간은 테이블의 사이즈에도 영향을 받지만, 테이블이 얼마나 잘게 쪼개어져 있는지에도 영향을 받는다. 예를 들어, 작은 크기의 Parquet 파일 몇 천개로 구성 되어 있는 경우라면 쿼리가 도는 것은 가능하지만, 쿼리가 매우 느리게 실행된다고 한다. 이것은 하나의 테이블의 데이터를 읽이 위해서 많은 갯수의 파일을 리스팅(listing)하고, 또 많은 파일을 열었다 닫았다 해야 하기 때문에 오버헤드가 발생한다. Delta Lake의 공식 블로그에서는 이것을 “the Small File Problem“라고 부른다.
실제로 30만 건 정도 되는 테이블을 1000개의 parquet 파일로 repartition 하여 저장하여 비교해보니 아래와 같은 차이가 있었다.
| rows | repartition | size | query time |
|---|---|---|---|
| 30만 | 8 | 73 MB | 9 sec |
| 30만 | 1000 | 100 MB | 42 sec |
1000개의 Parquet 파일로 나눠진 경우가 쿼리 속도도 느리고, 데이터 크기도 더 큰 모습을 볼 수 있다.
이런 Parquet 조각 문제를 쉽게 해결하는 방법은 잘게 쪼개진 Parquet 파일을 하나의 큰 파일로 병합하는 “Compaction” 작업을 해주며면 된다. Delta의 OPTIMIZE 명령어는 작은 크기의 파일에 대한 Compaction을 수행한다.
| rows | repartition | size | query time | |
|---|---|---|---|---|
| Compaction 전 | 30만 | 1000 | 100 MB | 42 sec |
| Compaction 후 | 30만 | 1 | 73 MB | 15 sec |
Compaction 작업이 파일들을 얼만큼 병합할지는 spark 옵션 중, spark.databricks.delta.optimize.maxFileSize에 의해 결정된다. 기본값은 1 GB로 세팅 되어 있다. 그래서 위의 실험에서 1000개로 나눠진 Parquet 파일이 하나의 Parquet 파일로 병합된 것이다. (Delta Lake는 분명 오픈소스인데 spark.databricks.라고 적혀있구먼…?) Delta의 compaction 작업은 파일 사이즈를 evenly-balanced 하게 분배한다고 한다. 만약 데이터 크기가 1.2 GB 였다면, 위의 maxFileSize에 따라 1 GB와 0.2 GB의 파일로 나뉘는게 아니라 0.6 GB 파일 2개로 압축 된다.
Delta에서 데이터를 읽는 행위는 모두 Snapshot Isolation으로 격리 되어 있기 때문에, 누군가가 Delta Lake에서 데이터를 읽는 도중에 OPTIMIZE 작업이 일어나도, 또는 OPTIMIZE 도중에 누군가가 데이터를 읽더라도 작업이 중단되지 않고 둘다 동시에 수행 될 수 있다.
Delta의 Compaction 작업은 멱등성(idempotent)을 가진다. 따라서 같은 경로, 같은 테이블에 대해 두 번 이상 OPTIMIZE 연산을 실행하더라도 데이터는 영향이 없다. 사실 2nd optimize 작업부터는 아무런 최적화가 이뤄지지 않는다.
If there are only a few small files, then you don’t need to run
OPTIMIZE. The small file overhead only starts to become a performance issue where there are lots of small files. You also don’t need to runOPTIMIZEon data that’s already been compacted. If you have an incremental update job, make sure to specify predicates to only compact the newly added data.
Delta의 공식 블로그에서는 “the Small File Problem“이 발생해서 쿼리 퍼포먼스에 문제가 생기는게 아니라면, 굳이 OPTIMIZE를 자주 돌릴 필욘 없다고 한다. 만약 데이터가 이미 충분히 압축된 상황이라면 OPTIMIZE 전후 큰 차이가 없기 때문이다. 또, 데이터가 증분(incremental)하게 추가되는 경우에도 전체 범위에 대해 압축할 필요 없고, 아래와 같이 범위를 지정해서 압축하는 걸 권장한다.
OPTIMIZE <TABLE_NAME> WHERE `date` >= '2024-01-01'
Auto Compaction
Delta Lake에 데이터를 쓰는 작업이 성공하면, 바로 직후에 Compaction을 수행해주는 옵션이다. Auto-compaction은 이전에 압축된 적이 없는 파일에 대해서만 수행된다고 한다.
만약 매번 쓰기 작업 마다 Compaction 작업이 일어난다면, 쓰기 작업이 느려질 수도 있으므로 파일이 얼만큼 쌓여야 Auto-compaction을 수행할지 결정할 수 있다. Spark의 spark.databricks.delta.autoCompact.minNumFiles 옵션을 통해 빈도를 조정할 수 있으며, 기본값은 50이다.
기능을 활성화 시키는 방법은 2가지 인데, Spark Session Config로도 할 수 있고, Table Property로도 제어할 수 있다.
- Table Property:
delta.autoOptimize.autoCompact - SparkSession Config:
spark.databricks.delta.autoCompact.enabled
Data Skipping
Delta Lake에선 쿼리 속도 향상을 위해 쿼리의 WHERE 조건에 따라 읽을 데이터를 선별 또는 스킵 하는 로직이 구현되어 있어 어떤 쿼리에서는 Parquet 파일에서 쿼리하는 것보다 더 빠르게 데이터를 조회할 수 있다.
Delta Statistics Columns
Delta의 Data skpping 정보는 Delta 테이블에 데이터 쓰기 작업을 할 때 자동으로 수집한다. 이 정보에는 아래 내용들이 담겨 있는데
- min/max values per columns
- null counts per columns
- total records
이런 통계 정보는 _delta_log/의 해당 버전 쓰기의 로그 파일에 새로 추가되는 Parquet 파일 별로 담겨서 저장 된다. 예를 들어, 쓰기 버전이 4 버전이었다면, _delta_log/000...0004.json 파일에 아래와 같이 기록된다.
// https://delta-io.github.io/delta-rs/how-delta-lake-works/architecture-of-delta-table/
{
"add": {
"path": "2-95ef2108-480c-4b89-96f0-ff9185dab9ad-0.parquet",
"size": 2204,
"partitionValues": {},
"modificationTime": 1701740465102,
"dataChange": true,
"stats": "{
\"numRecords\": 2,
\"minValues\": {\"num\": 11, \"letter\": \"aa\"},
\"maxValues\": {\"num\": 22, \"letter\": \"bb\"},
\"nullCount\": {\"num\": 0, \"letter\": 0}
}"
}
}
{
"remove": {
"path": "0-62dffa23-bbe1-4496-8fb5-bff6724dc677-0.parquet",
"deletionTimestamp": 1701740465102,
"dataChange": true,
"extendedFileMetadata": false,
"partitionValues": {},
"size": 2208
}
}
{
"commitInfo": {
"timestamp": 1701740465102,
"operation": "WRITE",
"operationParameters": {
"mode": "Overwrite",
"partitionBy": "[]"
},
"clientVersion": "delta-rs.0.17.0"
}
}
값을 보면, add 연산에 대한 부분의 stats 필드에 numRecords, minValues, maxValues, nullCount에 대한 정보가 담겨 있다. 이런 정보들을 활용해 Delta는 Parquet에서 쿼리하는 것보다 더 빠르게 값을 조회하고 반환해준다.
예를 들어, 전체 범위에 대한 행 갯수를 파악하는 SELECT COUNT(*) FROM <TABLE_NAME> 같은 쿼리를 수행한다면, delta가 읽는 각 Parquet 파일들에 대해 기록한 stats의 numRecords 값만 모두 더해주면 된다. 즉, Parquet 파일의 원본은 전혀 들여다 볼 필요가 없는 것이다.
단, 이런 통계 정보를 계산하는 것은 Parquet에서의 쓰기 작업과 비교해 오버헤드가 발생한다. 또, min/max를 계산하기 부담스러운 데이터 타입들(예를 들면 textual 데이터)은 이런 통계 정보를 계산하지 않도록 하고 싶을 수도 있다. 그럴 경우 아래의 두 Spark Session Config를 활용하자.
spark.databricks.delta.properties.defaults.dataSkippingNumIndexedColsspark.databricks.delta.properties.defaults.dataSkippingStatsColumns
dataSkippingNumIndexedCols 값에는 stats를 수집한 컬럼 갯수를 적는다. 기본값은 32로 첫 32개 컬럼에 대해서 stats를 계산한다. 만약 -1을 적어주면 모든 컬럼에 대해 stats 정보를 수집한다.
dataSkippingStatsColumns는 stats를 수집할 컬럼 이름을 comma-separated로 적어준다.
또는 Table Property로도 제어할 수 있는데 아래의 두 속성으로 지정할 수 있으며, 위의 Spark Session Config와 기능적으로 대응한다.
delta.dataSkippingNumIndexedColsdelta.dataSkippingStatsColumns
Get Column Statistics
Delta 쓰기에서 수집한 컬럼의 Stats 정보는 아래의 쿼리를 통해서 확인할 수 있다.
> DESC EXTENDED <TABLE_NAME> <COLUMN_NAME>
info_name info_value
-------------- ----------
col_name name
data_type string
comment NULL
min NULL
max NULL
num_nulls 0
distinct_count 2
avg_col_len 4
max_col_len 4
histogram NULL
Z-Ordering
Delta의 경우 OPTIMIZE를 수행할 때, ZORDER BY라는 절(clause)를 추가하여 Parquet 파티션의 데이터가 정렬되는 순서를 결정할 수 있다. 예시를 통해 좀더 살펴보자.
// https://delta.io/blog/2023-06-03-delta-lake-z-order/
+-----+-----+------------+---+---+------+---+---+---------+
| id1| id2| id3|id4|id5| id6| v1| v2| v3|
+-----+-----+------------+---+---+------+---+---+---------+
|id016|id046|id0000109363| 88| 13|146094| 4| 6|18.837686|
|id039|id087|id0000466766| 14| 30|111330| 4| 14|46.797328|
|id095|id078|id0000584803| 56| 92|213320| 1| 9|63.464315|
+-----+-----+------------+---+---+------+---+---+---------+
예를 들어 위와 같은 형식의 데이터가 1백만 행 정도 된다고 가정해보자. 이런 데이터에 id1 컬럼의 특정 값을 기준으로 데이터를 뽑은 쿼리를 돌리고자 한다.
SELECT
COUNT(*)
FROM
<TABLE_NAME>
WHERE
id1 = 'id016'
만약 테이블이 100개의 Parquet 파일로 파티셔닝 되어 있고, 또 id1='id016'라는 겂이 100개 파일 이곳저곳에 흩어진 상황이라면, 위의 쿼리는 100개의 Parquet 파일을 모두 탐색할 것이다.
그런데, 만약 100개의 Parquet의 데이터가 id1 컬럼을 기준으로 정렬되어 저장되어서 운 좋게 id1='id016'의 데이터를 하나의 Parquet 파일에 모을 수 있다면, 그런 상황에서 위의 쿼리는 오직 하나의 Parquet 파일만을 탐색할 것이다. 그리고 그 Parquet 파일에 대한 Delta Stats는 아래와 같이 기록될 것이다.
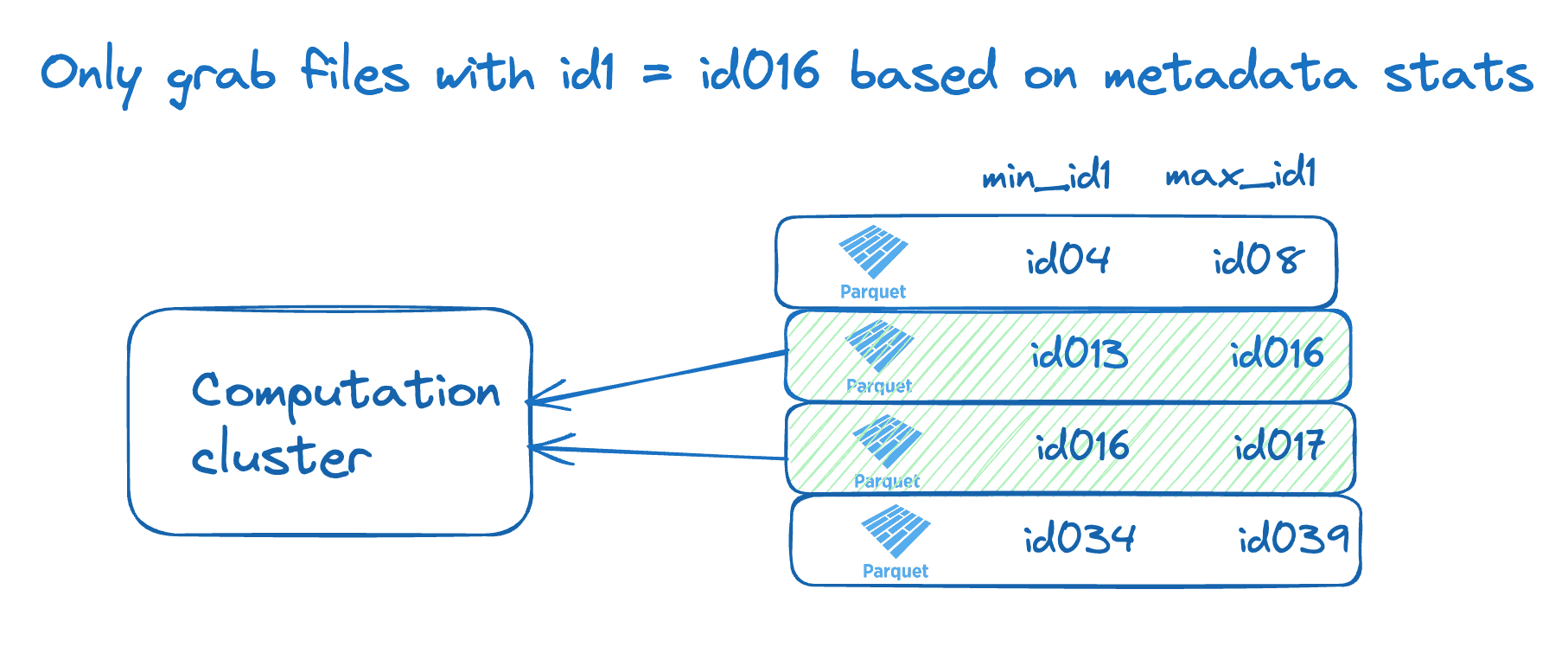
즉, 비슷한 성질의 데이터를 (여기서는 같은 id를 가진) 데이터를 하나의 파일에 묶어 지역성(Locality)를 갖추도록 만드는 최적화 테크닉이다.
이렇게 Delta를 구성하는 Parquet 파티션을 특정 컬럼을 정렬해 저장하는 방법을 Z-Ordering으로 수행할 수 있다. 해당 작업은 OPTIMIZE 작업과 함께 수행되며 아래와 같은 쿼리를 사용하면 된다.
OPTIMIZE <TABLE_NAME> ZORDER BY id1
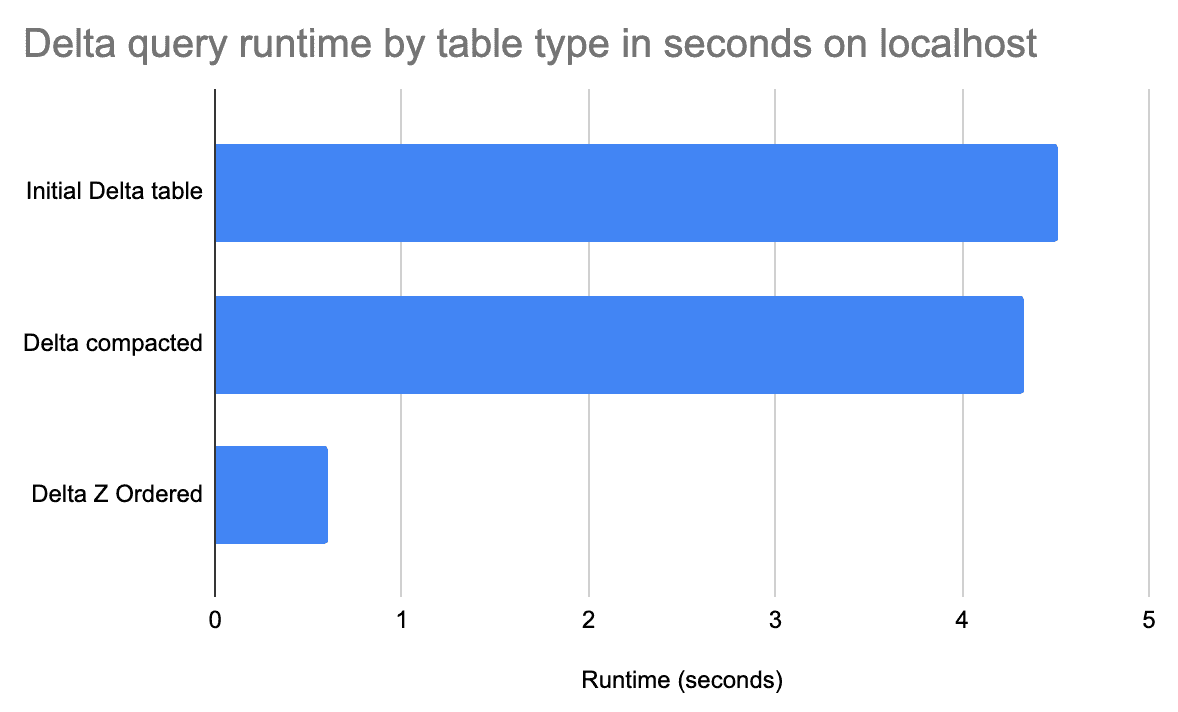
Delta의 블로그 아티클을 보면, 확실히 Z-Ordering을 준 컬럼에 대한 쿼리가 그렇지 않은 경우보다 훨씬 큰 향상을 보이는 걸 볼 수 있다.
Z-Ordering은 둘의 이상의 컬럼에 대해서도 수행할 수 있다. 하지만, Z-Ordering 컬럼 수가 많아질수록 여러 컬럼에 대해 좀더 빠른 쿼리를 얻겠지만, 그만큼 OPTIMIZE 과정에서 데이터 정렬이 더 필요하고, 또, 데이터의 지역성으로 얻는 이점이 저하될 수도 있다. 그렇기 때문에 해당 데이터를 쿼리하는 패턴을 면밀히 분석하고, 그에 맞춰 Z-Ordering할 컬럼을 결정하는 것이 중요하다.
또한 이런 Z-ordering에 기반한 파티션은 전체 데이터가 1 TB 이하, 파티션 별 데이터가 1 GB 이하라면 별로 추천하지 않는다는 내용도 Delta 블로그 포스트에 기술되어 있다.
You should not be partitioning tables under one terabyte in general. You also shouldn’t partition by a column that will have partitions with less than 1 GB of data.
Compare to Hive-style partitioning
Delta의 Z-Ordering과 Hive-style partitioning 둘다 비슷한 종류의 데이터를 하나의 파일 하나의 파일 청크로 묶기 위한 테크닉이다. 이를 통해 특정 쿼리를 수행할 때, 전체 데이터가 아닌 일부 데이터만 읽고 결과를 반환할 수 있다.
단, 차이점은 물리적인 구조에 있다. Hive-style partitioning은 비슷한 종류의 데이터를 같은 디렉토리(directory)에 배치한다. 그러나, Delta의 Z-Ordering은 비슷한 데이터를 디렉토리 분리 없이 하나의 디렉토리에 다른 종류의 데이터와 함께 모두 배치한다.
Partition 끼리 완벽하게 분리하는 Hive-style이 어떤 때는 강점을 가질 수 있다. 그러나 디렉토리 분리를 책임이 따르는데, 만약 파티션 컬럼에 너무 많은 Distinct 값들이 있을 때는 파티션 디렉토리가 너-무 많이 생길 것이고, 파티션 컬럼을 한번 지정하면 그것을 바꾸기는 정말 어렵고, 또 파티션 컬럼을 여러 개 지정하면 그만큼 파티션 디렉토리의 깊이(depth)가 깊어진다.
단, Z-Ordering과 Hive-style Partition은 베타적인 존재가 아니다. Delta에서도 Hive-style Partitioning을 할 수 있기 때문이다.
Analyze
앞에서 Delta는 쓰기 작업에 작동으로 컬럼의 Stats 정보를 수집한다고 했었다. 그런데, 이것을 직접 쿼리를 실행해 수행할 수 있으니 그것이 ANALYZE 명령어다.
-- need DBR 14.x above
ANALYZE TABLE <TABLE_NAME> COMPUTE DELTA STATISTICS
Delta의 최신 버전이 가리키는 Parquet 파일들을 모두 읽어서 Stats 정보를 다시 계산한다. Stats 정보를 다시 계산하는 것이기 때문에 _delta_log/에 커밋도 새로 생성되며, COMPUTE STATS라는 연산으로 기록된다. 단, 새로운 Parquet 파일이 생기거나 삭제되는 것은 아니다.
그외에도 몇가지 옵션과 함께 ANALYZE를 수행할 수 있는데,
ANALYZE ... COMPUTE STATISTICS NOSCAN- Delta 테이블의 사이즈만 새로 계산한다.
ANALYZE ... COMPUTE STATISTICS FOR COLUMNS ...- 일부 컬럼에 대해서 Stats 정보 다시 게산
ANALYZE ... COMPUTE STATISTICS FOR ALL COLUMNS- 전체 컬럼에 대해서 Stats 정보 다시 계산
왜 필요한가??
사실 Delta 쓰기 때마다 Stats 정보를 수집하고, 또 OPTIMIZE ZORDER 때도 Stats 데이터를 계산할 텐데 ANALYZE 명령어가 꼭 필요한 걸까?? 이 명령어를 언제 실행해줘야 하는 걸까??
이것저곳 찾아보니 Databricks Community에 이런 답변이 있었다: “What’s the best practice on running ANALYZE on Delta Tables for query performance optimization?”
ANALYZEwhenever the data has changed by about 10%- Make sure when you use
ANALYZE, you are specifying theCOLUMNSorPARTITIONSyou want to collect statistics for. Otherwise, as you have noted, it will re-analyze the entire table
암튼 테이블에 데이터 변화 좀(ex: 10%) 있었다거나 Stats 정보 수집 자체를 수동으로 컨트롤 하고 싶을 때, Stats 수집을 Delta 쓰기와 별도로 수행하고 싶은 용도로 명령어가 분리된게 아닐까 싶다.
Write Performance Compare
Delta의 경우 쓰기 작업을 할 때마다 Stats 데이터를 수집한다. 이것은 Parquet 쓰기 작업에서 없던 추가적인 작업이다. 이런 Stats가 몇몇 데이터 읽기 쿼리를 확실히 도움이 되겠지만, 과연 데이터 쓰기 때 Stats 정보 수집 때문에 생기는 오버헤드로 쓰기 퍼포먼스가 떨어지는게 아닐지 걱정이 되었다.

Databricks에서 출시한 2020년의 “Delta Lake: High-Performance ACID Table Storage over Cloud Object Stores” 논문에 따르면, Delta 쓰기의 경우 Stats 수집이 있지만, 그 오버헤드가 Parquet 쓰기와 비교해 미미한 수준이라고 한다. 아래는 논문의 해당 문단의 내용의 발췌다.
We also evaluated the performance of loading a large dataset into Delta Lake as opposed to Parquet to test whether Delta’s statistics collection adds significant overhead. Figure 7 shows the time to load a 400 GB TPC-DS store_sales table, initially formatted as CSV,
on a cluster with one i3.2xlarge master and eight i3.2xlarge workers (with results averaged over 3 runs). Spark’s performance writing to Delta Lake is similar to writing to Parquet, showing that statistics collection does not add a significant overhead over the other data loading work.
맺음말
Delta의 Data Skipping 기법은 SELECT * FROM <TABLE_NAME>으로 전체 데이터를 조회한다면 무용지물 일 수도 있다. 그러나 세상의 모든 쿼리가 Full Scan 쿼리가 아닐 것이고, 그런 특정 쿼리에 대해서 어떻게 퍼포먼스를 향상 시킬지 고민하는게 Delta Lake를 도입한 세상의 데이터 엔지니어가 해야 할 일인 것 같다.
어떤 프레임워크를 깊게 공부하는 건, 그 프레임워크에 대한 전문성을 갖추는 것 뿐만 아니라 문제를 해결하기 위해 그것이 채택한 기술도 함께 공부하게 되는 것 같다. 종종 “먄약 내가 대규모 분산처리 시스템을 다시 설계 한다면?” 같은 물음을 되뇌이며 그런 순간이 왔을 때 어떤 테크닉들을 써야 하는지 익히는 과정이라고 생각한다. 또, 어떤 기술적인 세부사항 보다는 그 테크닉이 문제를 합리적으로 접근하고, 설계되었는지를 고민하는 것 자체가 가치 있는 순간들인 것 같다.
Reference
- Databricks
- Delta Lake
- Delta Lake Official Blog