
Jump into Spark Sessions and Contexts
Databricks Certification 취득을 목표로 Apache Spark를 “제대로” 공부해보고 있습니다. 회사에선 Databricks Unity Catalog를 도입하려고 분투하고 있는데요. Spark와 좀 친해질 수 있을까요? 🎇 전체 포스트는 Development - Spark에서 확인해실 수 있습니다.
SparkSession? SparkContext?
이 글은 Apache Spark를 공부하면서 SparkSession과 SparkContext를 헷갈려 하던 나의 이야기를 담은 포스트이다.
Spark를 처음 공부하면, 강의나 공식문서를 통해선 SparkContext로 RDD를 만드는 걸 먼저 배웠다. 그런데, 회사에선 Databricks를 통해 “spark“란 이름의 변수로 사용하는 SparkSession를 먼저 사용했다.
최근엔 회사에서 Databricks에서 Unity Catalog로 마이그레이션을 했는데, UC에서는 “SparkContext를 사용하지 못 한다” Limitation도 있었다.
 Databricks: Shared access mode limitations on Unity Catalog
Databricks: Shared access mode limitations on Unity Catalog
문서를 읽어보면 SparkContext, SQLContext와 같이 Context API를 사용하지 못하고, 그와 관련된 .parallelize() 함수를 포함해 RDD API와 Dataset API도 사용 못 하게 된다;;
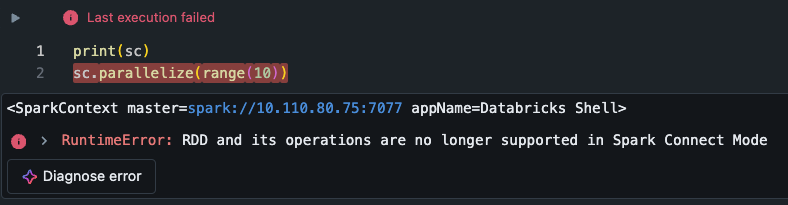 sparkContext에 접근하는 건 가능하지만,
sparkContext에 접근하는 건 가능하지만, .parallelize() 함수를 호출하는 건 안 된다.
이런 나의 경험들은 SparkContext와 RDD가 ‘구시대의 유물’이 아닌지 생각하게 했고, 관련된 개념들을 받아 들이는 데에, 알게모르게 장벽이 되었던 것 같다.
암튼 지금은 Databricks는 Databricks, Spark는 Spark라는 생각으로 SparkContext에 대해 받아들이고, 살펴보려고 한다.
Jump into SparkSession
회사에서 제일 먼저 익혔던 방식이 요 SparkSession이니 요걸 먼저 살펴보자.

Databricks에선 spark라는 변수로 pyspark든 scala spark든 접근할 수 있다. 요기에서 주로 쓰던 기능들은
spark.sql()- SQL 쿼리를 실행시킬 때 사용
spark.udf.register()- Spark UDF 함수를 등록할 때 사용
spark.table()- Hive 테이블에 접근할 수 있는 Spark DataFrame을 반환.
- 아직 Spark-Hive의 관계에 대해서 제대로 살펴보진 못 했음. TODO!
spark.catalog- Spark Session에서 접근할 수 있는 모든 데이터베이스와 그 안의 객체들(Table, View, Function)을 관리하는 API
spark.catalog.listTables(): 테이블 목록을 조회spark.catalog.setCurrentDatabase(): 현재 사용하는 Database를 지정
- Spark Session에서 접근할 수 있는 모든 데이터베이스와 그 안의 객체들(Table, View, Function)을 관리하는 API
spark.read- 데이터를 다양항 형식(csv, jso, parquet 등)에서 읽어들여 Spark DataFrame으로 반환.
spark.write- Spark DataFrame을 다양한 형식(위와 동일)으로 저장.
spark.conf- 현재 Spark Session의 설정을 관리하는 API
spark.streams- Spark Structured Streaming 관련 API
spark.SparkContext,spark.sqlContext- SparkSession에 내장된 Spark/Sql Context
- 그외 등등
본인이 지금 Databricks에서 spark로 사용하는 코드들을 본 것만 이 정도다. 여기에 몇 가지를 기능을 더 제공하는데, 나머지 기능들은 Spark 공식 문서 참고.
Unified entry point for interacting with Spark
Spark Session을 설명하는 가장 간단한 문장이다. spark라는 변수를 통해서 SQL로 실행하지, Hive 테이블 목록도 조회하지, UDF도 등록하지, Parquet 파일을 read/write 하기도 하지… 정말 많은 작업을 Spark Session을 통해서 수행한다.
암튼 지금까지 Spark Session에 대해 주저리 주저리 떠들었는데, 다음엔 이 포스트의 두번째 주제인 SparkContext로 넘어가보자.
Jump into SparkContext

Spark 공부를 시작할 때, RDD와 함께 가장 먼저 마주치는 녀석인 SparkContext다. 예전에는 SparkContext로 Spark를 접하는데, 당연 했을 지도 모른다. 왜냐하면, SparkSession은 spark 2.0부터 도입된 방식이기 때문이다.
SparkContext- spark 1.x
SparkSession- spark 2.0 (2016-07-26 출시)
참고로 작성일(24.08.27) 기준 Spark는 3.5.2 버전까지 나왔다. Spark 3.0 버전에서 가장 주요한 변경점은 AQE(Adaptive Query Execution)이고 다음 포스트에서 다뤄볼 예정이다. link
SparkContext는 RDD(Resilient Distributed Data)를 다루기 위한 entry point이다. RDD는 초기 Spark를 이루는 가장 기초적인 데이터 구조이다. RDD에 대해서도 지금 자세히 언급하기는 어려워서 별도 포스트에서 다뤄보겠다. 대충 원시적인 형태의 DataFrame이라고 보면 될 것 같다.
몇가지 코드를 통해 SparkSession와 SparkContext의 차이를 살펴보자.
Empty Data
Spark Session에서는…
scala> spark.emptyDataFrame
org.apache.spark.sql.DataFrame = []
Spark Context에서는…
scala> sc.emptyRDD
org.apache.spark.rdd.RDD[Nothing] = EmptyRDD[0] at emptyRDD at <console>:24
Range
Spark Session에서는…
scala> spark.range(10)
org.apache.spark.sql.Dataset[Long] = [id: bigint]
Spark Context에서는…
scala> sc.parallelize(1 to 9)
org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[1] at parallelize at <console>:24
Spark Session(이하 SS)의 .range()가 Spark Context(이하 SC)의 .parallelize()와 대응한다.
참고로 SC에도 .range() 함수가 있는데, 반환하는 RDD가 .parallelize()와 조금 다르다.
scala> sc.range(0, 10)
org.apache.spark.rdd.RDD[Long] = MapPartitionsRDD[3] at range at <console>:24
Read CSV
Spark Session에서는…
val df = spark.read
.option("header", "true") // 첫 번째 행을 헤더로 사용
.option("inferSchema", "true") // 데이터 타입을 자동으로 추론
.csv("/path/to/your/file.csv")
// DataFrame 내용 출력
df.show()
Spark Context 에선…
// CSV 파일을 텍스트 파일로 읽기
val rdd = sc.textFile("/path/to/your/file.csv")
// CSV 파일의 첫 번째 행을 헤더로 처리하고, 데이터를 분할
val header = rdd.first() // 첫 번째 행을 헤더로 추출
val data = rdd.filter(row => row != header) // 헤더를 제외한 데이터만 필터링
// 각 행을 콤마로 분할하여 RDD로 변환
val parsedData = data.map(line => line.split(","))
// RDD 내용 출력
parsedData.collect().foreach(row => println(row.mkString(", ")))
Spark Context 방식은 low-level API라서 그런지 CSV 파일을 읽는 간단한 작업도, 몇번의 처리를 거쳐서 수행되는 모습이다.
SQLContext
scala> val sqlContext = spark.sqlContext
res3: org.apache.spark.sql.SQLContext = org.apache.spark.sql.SQLContext@59aba9b3
scala> val df = sqlContext.read.json("./people.json")
df: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
scala> df.createOrReplaceTempView("people")
scala> sqlContext.sql("SELECT name, age FROM people WHERE age > 21").show()
+----+---+
|name|age|
+----+---+
|Andy| 30|
+----+---+
SQL Context는 spark가 읽은 데이터를 SQL을 사용해 쿼리하거나 조작하는 기능을 제공한다. 코드에 사용한 json 파일은 spark example에서 확인 가능하다.
HiveContext
사실 아직 Hive를 제대로 공부하지 않았아서, 이 부분을 제대로 이해하진 못 했지만, 현재 팀에서 Databricks에서 Hive Metastore를 사용하는 것을 보면, 대충 Spark SQL 쿼리가 Hive 테이블을 쿼리하는 거라고 짐작하고 있다.
Spark의 HiveContext는 Hive에 저장된 테이블을 Spark에서 쿼리하는 엔드포인트라고 이해하고 있다. 아래 코드를 사용하면, spark-shell을 실행한 경로에 Hive metastore를 로컬 세팅 해볼 수 있다.
scala> val df = spark.read.json("./people.json")
df: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
scala> df.write.mode("overwrite").saveAsTable("people")
24/08/29 17:54:56 WARN HiveConf: HiveConf of name hive.stats.jdbc.timeout does not exist
24/08/29 17:54:56 WARN HiveConf: HiveConf of name hive.stats.retries.wait does not exist
24/08/29 17:54:57 WARN ObjectStore: Version information not found in metastore. hive.metastore.schema.verification is not enabled so recording the schema version 2.3.0
24/08/29 17:54:57 WARN ObjectStore: setMetaStoreSchemaVersion called but recording version is disabled: version = 2.3.0, comment = Set by MetaStore seokyunha@127.0.2.2
24/08/29 17:54:57 WARN ObjectStore: Failed to get database default, returning NoSuchObjectException
24/08/29 17:54:58 WARN SessionState: METASTORE_FILTER_HOOK will be ignored, since hive.security.authorization.manager is set to instance of HiveAuthorizerFactory.
24/08/29 17:54:58 WARN HiveConf: HiveConf of name hive.internal.ss.authz.settings.applied.marker does not exist
24/08/29 17:54:58 WARN HiveConf: HiveConf of name hive.stats.jdbc.timeout does not exist
24/08/29 17:54:58 WARN HiveConf: HiveConf of name hive.stats.retries.wait does not exist
24/08/29 17:54:58 WARN ObjectStore: Failed to get database global_temp, returning NoSuchObjectException
위의 명령어를 실행하면, 로컬에 두 폴더가 자동으로 생성된다.
./metastore_db/- 자동으로 생성된 Hive Metastore다.
- Apache Derby라는 순수 자바로 구현된 RDBMS다.
- 약간 sqlite 같은 녀석임.
- 이곳에 Database, Table 그리고 컬럼 정보 등이 저장된다.
./spark-warehouse/people.saveAsTable()로 저장한 Hive 테이블이 물리적으로 저장된 경로
로컬에 Hive Metastore를 구축했기 때문에, spark-shell을 종료하고 다시 실행해도 같은 경로에서 실행만 한다면, metastore_db 폴더를 통해 이전에 저장했던 Hive 테이블 정보를 다시 사용할 수 있다.
scala> spark.sql("SELECT * FROM default.people").show
+----+-------+
| age| name|
+----+-------+
|NULL|Michael|
| 30| Andy|
| 19| Justin|
+----+-------+
HiveContext를 사용해서 HiveQL을 날리려면 아래와 같이 하면 된다.
scala> import org.apache.spark.sql.hive.HiveContext
scala> val hiveContext = new HiveContext(sc)
scala> hiveContext.sql("SELECT * FROM default.people")
Multiple SparkSession, but only one SparkContext
하나의 Spark Cluster 안에 SparkSession은 동시에 여러 개 존재하거나 생성할 수 있지만, SparkContext은 오직 하나만 존재한다.
즉, 여러 SparkSession이 하나의 같은 SparkContext를 서로 공유한다는 뜻이다. Spark에서 Multiple Spark Session을 지원하기 때문에, 각자의 Databricks 노트북(또는 Jupyter 노트북)에서 생성하는 TEMP VIEW의 이름이 같아도 서로 간섭 하지 않는다.
Databricks에서 서로 다른 두 노트북에서 같은 클러스터를 붙여 확인해보면
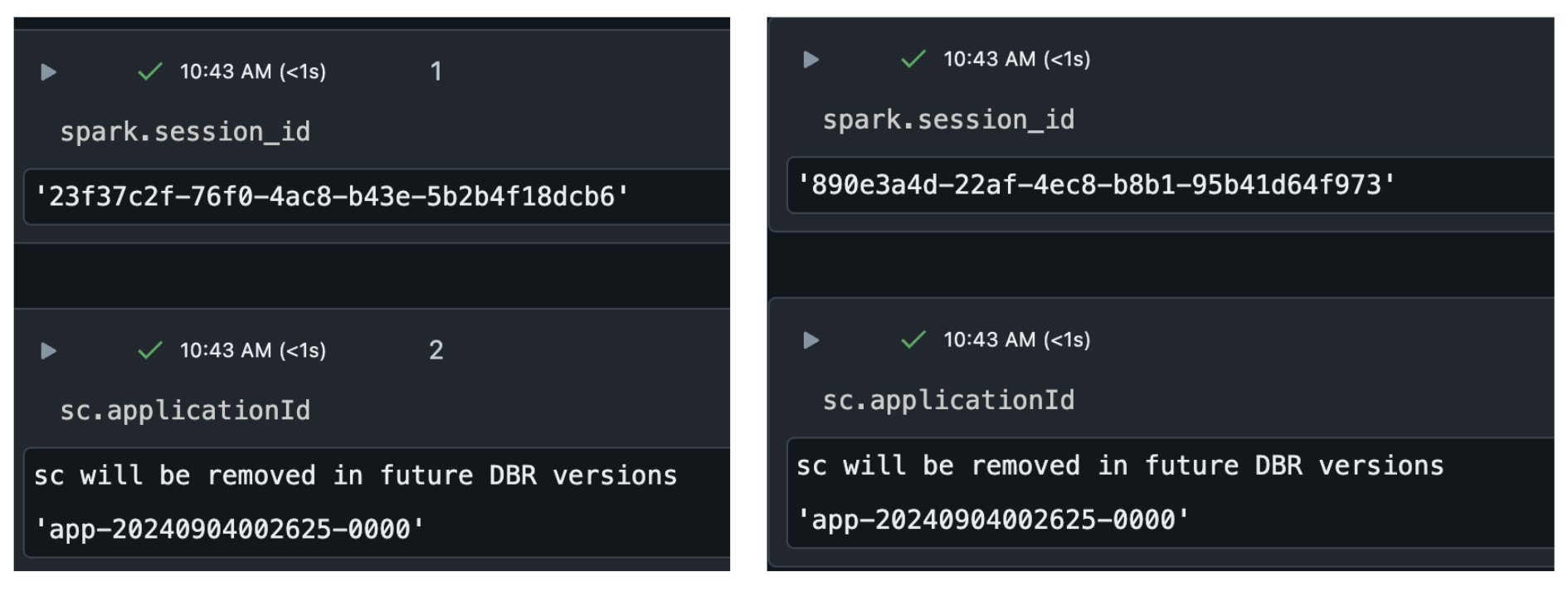 Spark Session은 서로 다른 ID를 같지만, Spark Context는 같은 ID를 갖는다.
Spark Session은 서로 다른 ID를 같지만, Spark Context는 같은 ID를 갖는다.
위와 같이 sc의 ID는 동일한 걸 볼 수 있다. 이때 ID는 어떤 YYYYMMDDHHmmss 포맷인데, Databricks 클러스터가 시작된 UTC 시간이 ID 값이 되었다.
맺음말
이번 포스트를 작성하면서, SparkSession과 SparkContext, SQLContext, HiveContext까지, 모호하게 알던 개념을 이해하게 된 것 같다. Spark와 Hive도 둘이 왜 맨날 엮이는지 궁금했는데, 이것도 어렴풋이 알게 된 것 같다. “RDD와 DataFrame의 차이점은?” 같은 질문도 새롭게 생겨났다.
물론 아직도 Databricks의 Shared-mode에서 Unity Catalog에서 왜 SparkContext, SQLContext, RDD를 제한하게 되었는지는 잘 모르겠지만, Spark를 공부하다보면 곧 알게 되겠지…!?