
Spark Adaptive Query Execution
Databricks Certification 취득을 목표로 Apache Spark를 “제대로” 공부해보고 있습니다. 회사에선 Databricks Unity Catalog를 도입하려고 분투하고 있는데요. Spark와 좀 친해질 수 있을까요? 🎇 전체 포스트는 Development - Spark에서 확인해실 수 있습니다.
Adaptive Query Execution이란?
본인 회사는 2018년부터 Databricks를 도입해 Spark를 사용하고 있었다. 사용한지 오래 되어서 그런지 Databricks Job들에 정말 다양한 Spark Config들이 세팅 되어 있었다. 요즘 회사에서 사용하는 Spark Config를 정리해서 발표를 준비하고 있는데, spark.sql.adaptive.enabled라는 config가 내 눈길을 끌게 되었고, 그렇게 오늘의 주제인 Adaptive Query Execution(이하 AQE)에 대해 살펴보게 되었다.
AQE 기능은 Spark 3.0부터 도입된 Spark Optimization 테크닉이다. 참고로 Spark 3.0은 2020년 6월에 공개 되었고, Spark 3.2부터는 따로 설정하지 않으면 AQE enabled가 기본값이다.
Dynamically coalescing shuffle partitions
Spark에서 거대한 데이터를 다룰 때, 셔플링(shuffling)은 쿼리 퍼포먼스에 큰 영향을 끼치는 요소이다. 셔플링은 Executor가 처리하던 파티션 데이터를 다시 재정렬 하는 과정으로 groupByKey, reduceByKey, join, distinct, repartition 등의 연산을 수행할 때 발생한다.
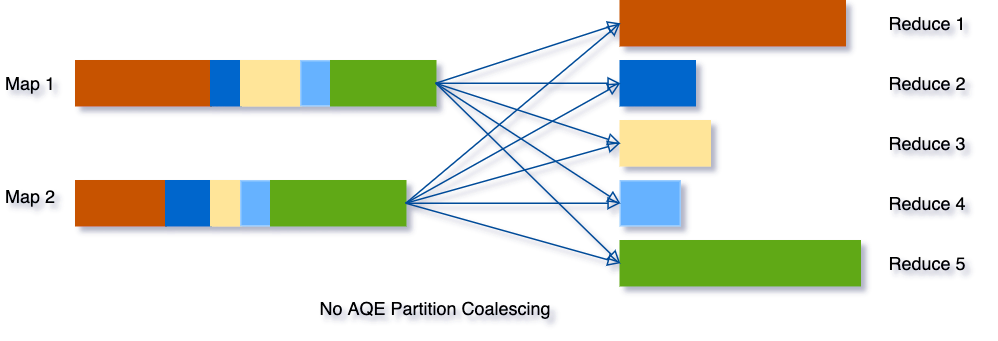 Databricks: Adaptive Query Execution
Databricks: Adaptive Query Execution
위의 사진이 Partition이 Shuffling 되는 과정을 표현한 것으로 색깔별로 데이터가 재정렬 되는 걸 볼 수 있다. 위의 경우, 셔플된 파티션(이하 셔플 파티션)이 5개로 셔플링 되었는데, [2, 3, 4]번 데이터 경우 크기가 작고, [1, 4]번 데이터는 크기가 상대적으로 큰 것을 볼 수 있다. 이 경우, [2, 3, 4]번 데이터 처리는 금방 되더라도 [1, 4]번 데이터의 처리가 완료 될 때까지 기다려야 한다.
 Databricks: Adaptive Query Execution
Databricks: Adaptive Query Execution
Spark AQE는 어짜피 전체 작업이 완료 되려면, [1, 4]번 데이터의 작업을 기다려야 하는데, 이럴 꺼면 [2, 3, 4]번 데이터를 뭉쳐서 [1, 4]과 비슷하게 만들고, 연산에 사용하는 Task 갯수도 줄이는게 효율적이라고 판단한다.
본래 Spark에는 셔플링 후의 파티션 갯수를 지정하는 spark.sql.shuffle.partitions 값이 있고, 따로 설정하지 않는다면 “200“이 기본값이다. 만약 이 값을 그대로 따른다면, 셔플 파티션 갯수가 항상 200개씩 만들어진다. 너무 많은 파티션은 많은 태스크를 만들고, 이는 작업 부하로 이어지므로 셔플 파티션을 적절히 세팅 해야 한다.
요 Dynamic coalescing이 어떻게 구현되어 있는지는 모르겠지만, spark.sql.adaptive.coalescePartitions.initialPartitionNum으로 초기 셔플 파티션을 지정해야 하는 걸로 봐서는 아마 처음엔 비효율적인 셔플 파티션을 한번 수행하고, 그 이후에 AQE Optimizer가 돌면서, Coalescing을 수행해 셔플 파티션 갯수를 줄여주는 것 같다. 즉, 셔플된 데이터를 처리하는 후속 작업이 더 적은 갯수의 Task를 사용하게 되는 것.
참고로 coalescePartitions.initialPartitionNum을 따로 지정하지 않으면, shuffle.partitions 값을 그대로 쓰고, 그것의 기본값은 200이다.
셔플 파티션을 얼만큼 병합하는지는 2가지 기준이 존재한다. spark.sql.adaptive.coalescePartitions.parallelismFirst라는 값이 참/거짓인지에 따라 다르다.
parallelismFirst = true- 동시처리를 최대화 하기 위해, 데이터를 너무 많이 병합하지 않고 파티션을 적당히 병합한다.
- 그래서 셔플 파티션의 병합이
spark.sql.adaptive.coalescePartitions.minPartitionSize에 명시된 값(default:1Mb)의 크기 가 되면, 더이상 병합하지 않는다. 또,coalescePartitions.minPartitionSize값은 아래에 나올advisoryPartitionSizeInBytes값의 최대 20% 정도로만 설정 가능하다. - Spark 3.2.0부터 도입된 설정값으로, Dynamic Coalescing으로 인한 성능 저하를 방지하기 위함.
parallelismFirst = false- 본래 Dynamic Coalescing의 동작 방식을 사용한다.
advisoryPartitionSizeInBytes의 값(default:64MB)에 가깝도록 셔플 파티션을 병합한다.
Dynamically switching join strategies
일단 요걸 이해하기 전에 Spark의 Join 방식 2가지를 이해해야 한다.
Sort Merge Join
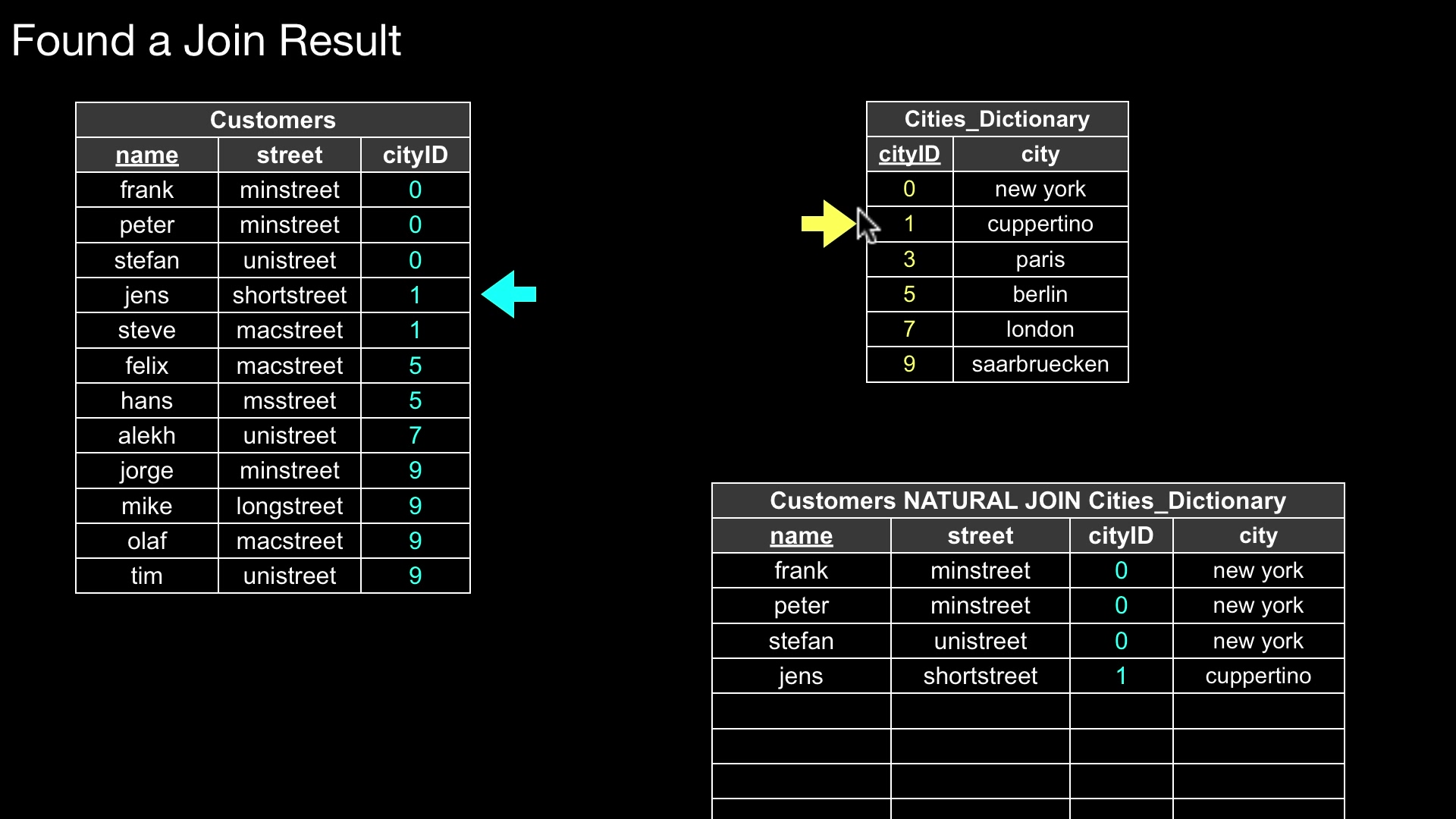 Prof. Dr. Jens Dittrich: Sort-Merge Join, Co-Grouping
Prof. Dr. Jens Dittrich: Sort-Merge Join, Co-Grouping
위의 그림과 같이 Customer 테이블과 Cities_Dictionary 테이블을 cityID라는 컬럼을 기준으로 join 하는 경우를 살펴보자.
먼저, 두 테이블을 cityID를 기준으로 정렬(Sort) 한다. 위의 그림 상으로는 이미 정렬된 상태로 나와 있다.
그 다음은 병합(Merge) 한다. 각 테이블에서 cityID의 가장 처음 값에 포인터(Pointer)를 두고, 하나씩 하나씩 행을 순회한다. 만약 두 테이블의 값이 일치(=) 한다면 병합을 수행하고, 매칭 되지 않는 다면, 비교 하는 오른쪽 테이블의 포인터가 다음 행을 가리키게 한다.
시간 복잡도를 얘기하자면, $O(A \log A + B \log B)$.
Broadcast Hash Join
요 Join 방법은 Broadcast Join과 Hash Join, 두 방식이 결합한 방식이다.
Hash Join에 대해서 먼저 설명하면, 아래와 같은 pseudo-code를 가진다.
def hash_join(left: Table, right: Table, join_key: Column):
hash_table = {}
# Generate hash table
for idx, row in left:
hash_key = row[join_key]
if hash_key in hash_table:
hash_table[hash_key].append(idx)
else:
hash_table[hash_key] = [idx]
ret = []
# Do join using hash table
for idx, row in right:
hash_key = row[join_key]
if hash_key in hash_table:
for idx in hash_table[hash_key]:
ret.append(row.join(left[idx]))
else:
continue
return ret
테이블 중 하나로 Hash Table을 만들고, 반대 테이블에서 그 Hash Table과 매칭하는 행이 있는지 찾아서 Join 하는 기법이다. 처음에 Hash Table을 만드는 데에 선형 시간이, 그리고 반대 테이블에 Hash Table을 적용해 결과를 만드는 데에 선형 시간이 걸린다. 시간 복잡도는 $O(A + B)$.
Broadcast Join은 연산의 대상이 되는 테이블 둘 중 하나가 충분히 작을 때 사용하는 기법으로, Small 테이블 전체를 모든 Worker 노드에 뿌리고, 그 안에서 Join을 수행하는 기법이다.
본래 Spark에서의 Join은 두 테이블을 셔플링 한 후에, 같은 키를 가진 레코드가 같은 파티션에 배치 한다. 그리고, 같은 키를 가진 두 테이블의 파티션을 같은 Worker 노드에 배치하고, 그 안에서 로컬 Join을 수행한다.
반면, Broadcast Join은 셔플링 과정이 없다. Small 테이블과 Large 테이블 둘다 셔플링 하지 않고, 처음 파티션 그대로 각 워커에 분배되어 그곳에서 로컬 Join 된다. 셔플링이라는 연산을 하지 않기 때문에 계산과 네트워크 이동에서 이득을 얻는다.
암튼 정리하면, Broadcast Hash Join은 Broadcast Join인데, 로컬 Join의 방식이 Hash Join이라는 말!!
Dynamically switching join strategies: Sort-Merge → Broadcast Hash
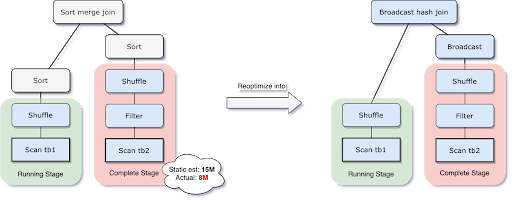 Databricks: Adaptive Query Execution
Databricks: Adaptive Query Execution
Spark AQE는 Join 되는 두 테이블의 사이즈를 runtime에서 확인하고, 만약 한쪽 테이블의 크기가 충분히 작다면, Broadcast Hash Join으로 변경 후 처리한다.
테이블 크기가 충분히 작은지는 spark.sql.adaptive.autoBroadcastJoinThreshold에 명시된 값으로 판단한다. 만약, 따로 설정해주지 않는다면, spark.sql.autoBroadcastJoinThreshold의 값을 그대로 사용하며, 그때의 기본값은 10Mb이다.
Dynamically optimizing skew joins
데이터의 뷸균형(skewing)은 파티셔닝 된 데이터를 다룰 때, 성능 저하를 야기할 수 있다.
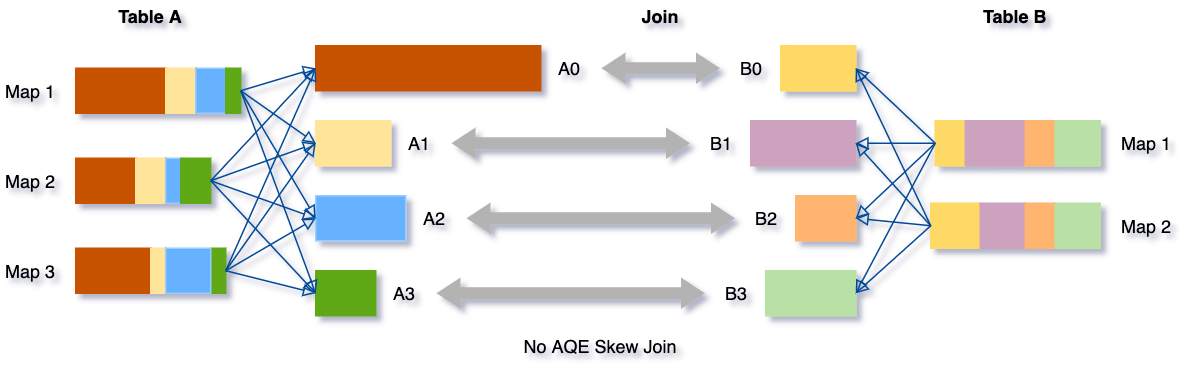 Databricks: Adaptive Query Execution
Databricks: Adaptive Query Execution
위의 그림의 경우, A0 데이터가 특별히 많은 상태라 A0와 B0를 Join 하는 것이 병목으로 작용한다. Spark AQE에선 이렇게 특별히 하나의 파티션에 데이터가 많은 경우를 핸들링 하기 위해, 그 파티션을 절반 정도로 분할하여 Join을 수행한다.
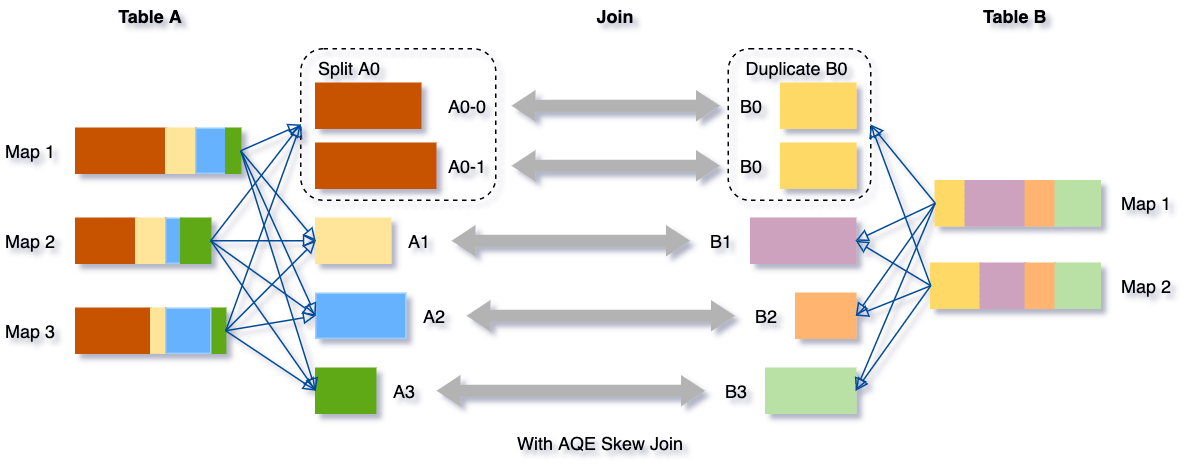 Databricks: Adaptive Query Execution
Databricks: Adaptive Query Execution
위의 그림에서 A0-0, A0-1이 분할된 파티션에 해당하고, Right Table의 $B0$는 분할된 $A0$ 파티션과 Join 하기 위해 복제되었다.
파티션 갯수가 많아짐에 따라 Task 수는 많아졌지만, Executor 수가 충분하다면 전체 작업의 처리 시간이 더 개선될 것이다.
특정 파티션이 skew 되어있는지는 아래 두 요소를 기준으로 판단한다.
spark.sql.adaptive.skewJoin.skewedPartitionFactor- 데이터의 파티션 사이즈의 중앙값(median)을 기준으로 이 값(default:
5.0)의 배수보다 크다면, Skewed Partition이라고 판단한다. - 단,
skewedPartitionFactor조건과 아래의skewedPartitionThresholdInBytes조건을 동시에 만족해야 함.
- 데이터의 파티션 사이즈의 중앙값(median)을 기준으로 이 값(default:
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes- 데이터의 파티션 사이즈가 이 값(default:
256Mb)보다 크다면, Skewed Partition이라고 판단한다. - 이때, Dynamic Coalescing에 관여하는
spark.sql.adaptive.advisoryPartitionSizeInBytes값보다는 크도록 설정할 것을 권장한다. 그렇지 않으면, Skewed Partition이 분할된 후에 Dynamic Coalescing이 발생하기 때문.
- 데이터의 파티션 사이즈가 이 값(default:
Performance Improvement
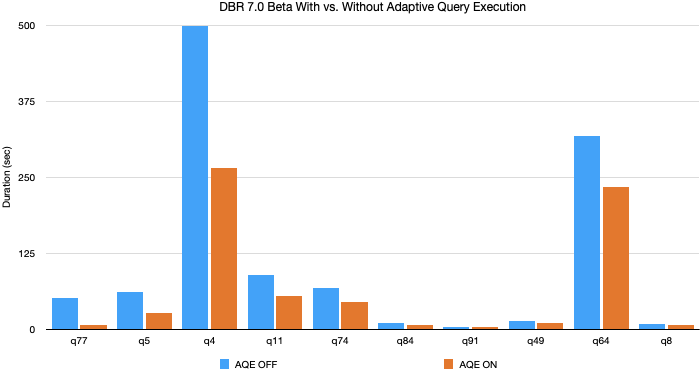 Databricks: Adaptive Query Execution
Databricks: Adaptive Query Execution
Databricks의 벤치마크에 따르면, Spark AQE를 활성화 했을 때 대부분의 쿼리에서 성능 개선이 있었다고 한다. 다만, 구체적으로 어떤 쿼리인지는 밝히지 않았다. (늘 그렇든 벤치마크는 다 믿으면 안 된다.)
Spark AQE 기능은 쿼리가 아래의 조건을 만족할 때 사용할 것을 권장한다고 한다.
- Streaming 처리를 하는 쿼리가 아닐 것
- 적어도 하나의 데이터 셔플링을 가질 것
- Join, Aggregation, Window Query
- 또는 적어도 하나의 서브 쿼리가 있을 것
맺음말
Spark 2.x 세대에서 개발된 Spark Query Optimization 기법은 Static Optimization으로 Spark SQL 쿼리를 분석해 쿼리 순서를 재배열하여 개선하거나, 어떤 최적화 규칙에 따라 쿼리를 최적화 했었다.
반면에 Spark AQE는 완전히 runtime에 이뤄지는 쿼리 최적화 기법이다. 데이터가 셔플링 된 이후에 이뤄지며, 셔플 파티션의 통계값(statistics)를 기준으로 데이터를 병합하기도 하고, 분할하기도 하며 더 저렴한 Join(Broadcast Join)으로 바꾸기도 한다.
이런 변화는 더이상 최적화를 위해 데이터 자체의 특성을 조사 할 필요는 없앴다고 한다…고는 하지만 그럼 데이터 엔지니어가 하는 일이 없어지는 걸 ㅋㅋㅋ Spark AQE가 우리의 부담은 덜어줬지만, 처리하는 데이터와 Spark SQL을 다시 검토하는 과정은 늘 필요한 것 같다.
암튼, 이렇게 Spark Config 중 하나인 spark.sql.adaptive.enabled에 대해 꼼꼼히 살펴보았고, 다른 주제들을 또 살펴보자 ㅎㅎ