
Spark Jobs, Stages and Tasks
Databricks Certification 취득을 목표로 Apache Spark를 “제대로” 공부해보고 있습니다. 회사에선 Databricks Unity Catalog를 도입하려고 분투하고 있는데요. Spark와 좀 친해질 수 있을까요? 🎇 전체 포스트는 Development - Spark에서 확인해실 수 있습니다.
들어가며
 Databricks
Databricks
회사에서 Spark를 Databricks에서 사용하면서, 요런 Spark Jobs 화면과 Stage 들이 어떤 의미를 가지는지 늘 궁금했다.
Spark Action과 Spark Job
RDD 또는 DataFrame에 어떤 연산을 수행해 결과를 생성하는 연산이다. Action을 호출하면, Spark가 연산에 대한 DAG 그래프를 생성해 실행하고, 그 결과를 로컬 변수에 담는다.
Spark Action은 Spark에서 만든 Query Execution Plan이 실제로 실행되는 즉, “Lazy Evaluation”을 실행하는 행동이다. Spark Action의 예시로는 아래 작업들이 있다.
.collect().count().take(n).reduce(func).saveAsTextFile(path)
Spark Transformation과 Spark Stage
Spark Transformation은 기존 RDD에서 새로운 RDD를 생성하는 연산이다. 모든 Transformation은 즉시 실행되지 않는다. Query Plan에 반영만 되고, Spark Action이 트리거 될 때에 계산되는 것이다. Spark Transformation의 RDD 연산의 예시로는 아래 연산들이 있다.
.map().filter().groupByKey().sortByKey().join()
그리고 Transformation 연산은, 그것이 하나의 노드에서 바로 수행 할 수 있는지, 아니면 처리할 데이터가 여러 노드에 분산되어 있어 연산을 처리하기 위해 노드 사이에 데이터 이동이 필요한지에 따라 Narrow Trans.와 Wide Trans.로 나뉜다.
Narrow Transformation
![]() Databricks: Data Engineers Guide to Apache Spark and Delta Lake
Databricks: Data Engineers Guide to Apache Spark and Delta Lake
연산에서 처리하는 각 input 파티션의 오직 하나의 output 파티션의 결과에만 기여하는 연산이다. 대표적으로 .filter() 또는 .where() 연산이 이에 해당한다.
RDD의 .map() 함수도 1-to-1 연산이기 때문에 Narrow Trans.에 해당한다.
.union() 연산도 각 input 파티션이 union RDD의 한 파티션으로 그대로 이동하기 때문에 Narrow Trans.로 분류한다.
또, 만약 Join 하는 두 파티션이 서로 “co-partitioned” 되어 있다면, Join을 위한 셔플링이 발생하지 않기 때문에 Narrow Trans.가 된다. 데이터가 “co-partitioned” 되어 있다는 말은 Join 하는 데이터가 Join Jey를 기준으로 파티션 되어 있는 경우를 말한다.
Wide Transformation
![]() Databricks: Data Engineers Guide to Apache Spark and Delta Lake
Databricks: Data Engineers Guide to Apache Spark and Delta Lake
Wide는 Narrow와 반대로 연산을 위해 데이터의 이동이 발생한다. 이것을 “셔플링(Shuffling)”이라고 한다.
.groupByKey()로 각 파티션에 흩어진 데이터를 그룹핑 하거나, 서로 co-partitioned 되지 않은 두 데이터를 Join 할 때도 셔플링이 발생하며, 이들을 Wide Trans.로 분류한다.
또, 데이터를 정렬하는 .sortByKey() 역시 한 파티션에 있던 데이터가 다른 N개 파티션으로 흩어질 수 있기 때문에, Wide Trans.이다.
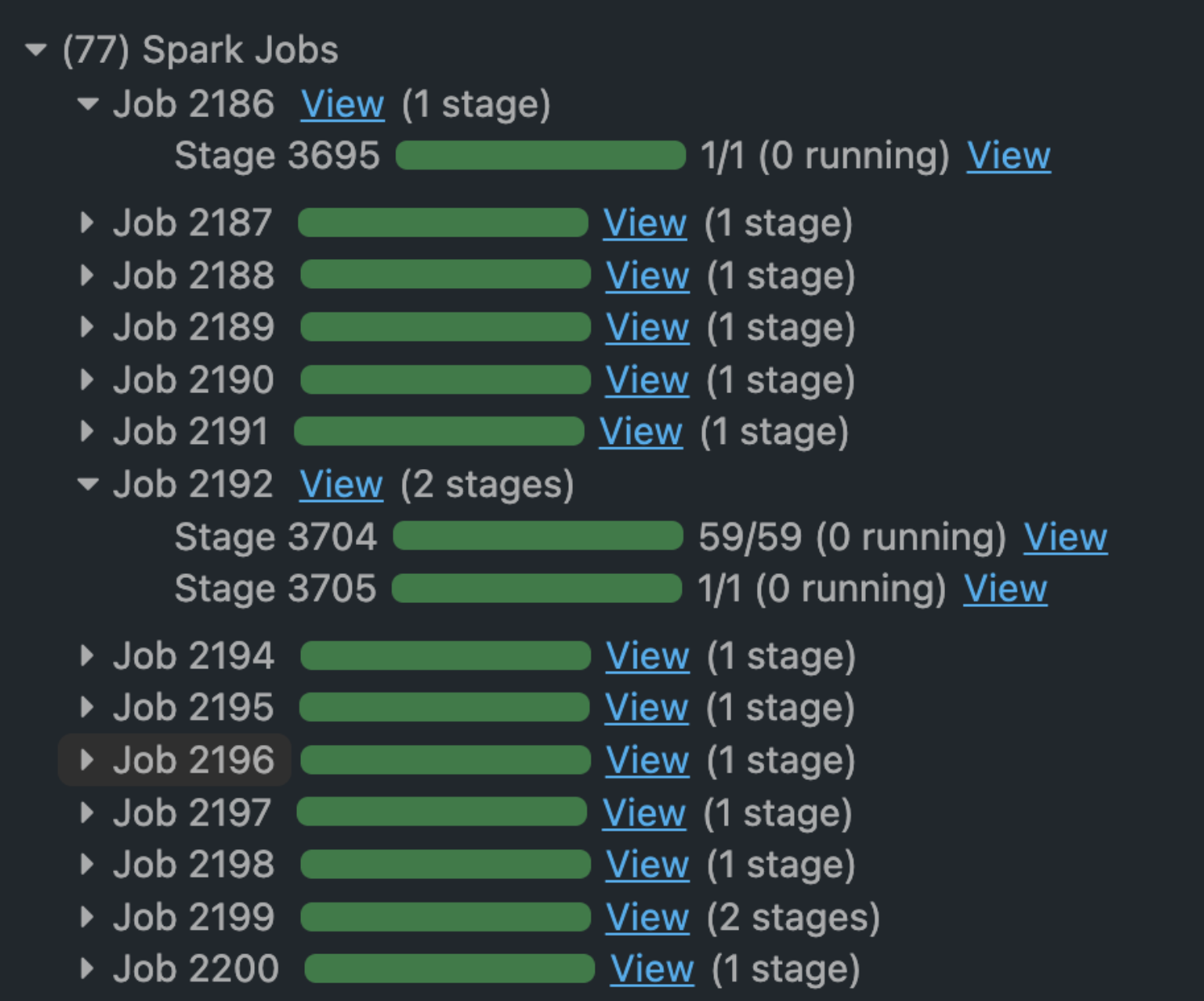
Skipped Stage
The grayed boxes represents skipped stages. Spark is smart enough to skip some stages if they don’t need to be recomputed. If the data is checkpointed or cached, then Spark would skip recomputing those stages. - Databricks
즉, Spark는 이미 계산되어 checkpoint에 담았거나 캐싱한 Stage의 데이터는 다시 계산하지 않고 재사용한다.
RDD의 Partition과 Spark Task
Partition은 RDD의 개념으로, Spark Executor가 데이터를 처리하는 최소 단위이다. 관점은 논리적, 물리적 2가지 관점에서 모두 해석하는데,
[논리적 관점]
- RDD 데이터는 파티션 단위로 분할되어 처리된다.
- 각 파티션은 불변성을 가지고, Transformation을 수행하면 기존 RDD에서 새로운 RDD가 생기는 것이다.
- 파티션이 처리되는 방식에 따라 Narrow Trans.와 Wide Trans.로 분류한다.
[물리적 관점]
- Spark Executor에는 데이터가 Partition 단위로 물리적으로 존재한다.
- 논리적 관점에서는 파티션 크기를 논하지 않았지만, 물리적 환경에서는 파티션 크기를 적절히 설정하는 것이 중요하다.
- 같은 데이터를 처리하더라도
- 파티션 사이즈가 너무 작으면 잦은 I/O로 오버헤드가 발생하며
- 파티션 사이즈가 너무 크면, 특정 노드에 부하가 커질 수도 있고, 더 많은 Memory가 필요해 Spill이 발생할 수 있다.
하나의 Partition은 하나의 Task에 대응되고, 하나의 Task는 Executor의 CPU 1 core를 사용해 처리한다. 정확히 말하자면, spark.task.cpus에 명시된 값만큼의 CPU core를 사용해 처리하는데, 이것의 default 값이 1이기 때문에, 하나의 Task를 처리하기 위해 1 core를 사용한다고 말한다. 참고로 spark.task.cpus 값은 정수 단위로만 조정할 수 있다.
Executor 쪽에도 튜닝할 수 있는 값들이 좀 있는데,
spark.executor.cores- Executor에서 사용할 수 있는 총 CPU 코어 갯수.
- Standalone 모드를 사용한다면, Executor의 가용 코어를 모두 사용한다.
spark.executor.memory- 하나의 Task가 사용 가능한 Memory 사이즈
- 기본값은
1g
위에서 살펴본 Stage는 N개 Task를 묶은 개념이다. 그리고 각 Task는 서로 다른 파티션을 처리하기 때문에 서로 독립적으로 실행 가능하다. 따라서 같은 Stage에 묶인 Task는 각 노드에서 병렬로 실행된다.
Spark Task와 RDD Partition은 1-to-1 관계이기 때문에, 결국 Task 갯수는 RDD를 얼마나 파티션 하느냐에 달렸다. 그리고 이 값은 아래의 두 Spark Config에 의해 결정된다.
spark.default.parallelism- RDD 데이터에 Transformation 연산을 했을 때, 리턴되는 파티션 갯수.
- 기본으로 세팅된 값은 아래의 규칙을 따른다.
.reduceByKey(),.join()과 같은 연산은 parent RDD 중 가장 큰 파티션 갯수를 parallelism으로 갖는다..parallelize()와 같이 parent RDD가 없는 경우는- Local Mode에서는 local machine의 코어 갯수로
- Standalone Mode에서는 Worker Node의 코어 갯수로
- Mesos와 그외 모드에서는 문서를 참고.
spark.sql.shuffle.partitions- 데이터를 셔플링 할 때의 기본 파티션 갯수이다.
- 기본값은
200
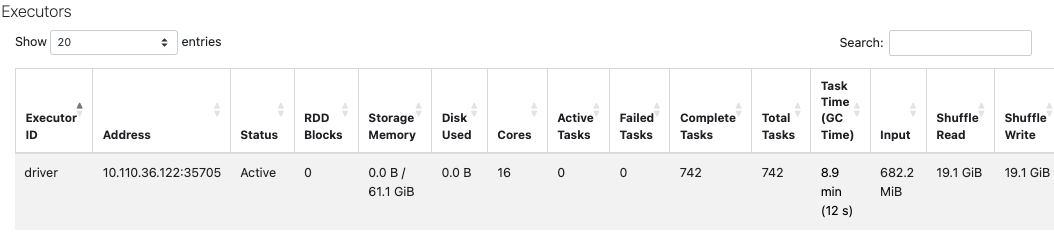 Databricks
Databricks
Spark UI의 한 화면 중 하나인데, Spark 작업을 최적화 하면서 많이 보던 화면이다. 두 태스크를 비교하여, 데이터 I/O과 Spark Config가 모두 같다면, Task 갯수가 적어지는 방향으로, 그리고 Total Task Time이 줄어드는 방향으로 최적화 되고 있는지 체크 했었다.