
Parquet 포맷의 구조 다시보기
데이터 엔지니어로서 일을 한지 벌써 3년이 넘었다…! 그런데 그동안 맨날 써온 .parquet 포맷을 내가 제대로 알고 있는게 맞나?라는 생각이 들었다. Parquet도 포맷이 v2까지 나온 꽤 오래되고 유서 깊은 포맷이고, 또 최근에는 Parquet Variant 타입 관련해서도 작업을 하고 있는데, 내가 이 포맷에 대해 자신 있게 얘기할 수 있는지 스스로 돌아보게 되었다. 그래서 이번 기회에 Parquet를 다시 보고 내가 부족했던 부분들은 채워넣어보려고 한다.
Parquet 포맷의 내부를 먼저 살펴볼 건데, Row Group, Column Chunk, Footer, Magic Number 등등 용어들이 나오지만, 일단은 내가 이해하기 쉬운 방향으로 글을 적어보려고 한다.
큰 그림으로 이해하기
일단 Parquet 파일을 크게 살펴보면, 데이터 섹션과 푸터 섹션으로 나뉜다.
데이터 섹션은 실제 저장된 데이터가 있는 곳이고, 푸터 섹션은 저장된 데이터에 대한 스키마 정보와, 통계 정보, 접근할 때의 offset 정보가 있다.
- 데이터 섹션
- 푸터 섹션
(데이터 섹션 + 푸터 섹션) 앞 뒤로 PAR1으로 매직 넘버가 있다. 그래서 정확히는 PAR1 + 데이터 섹션 + 푸터 섹션 + PAR1 구조로 Parquet 파일이 만들어진다.
Parquet 데이터를 쓸 때는 데이터 -> 푸터 순서로 작성 된다. 하지만, Parquet 데이터를 읽을 때는 반대로 푸터 -> 데이터 순서로 접근한다.
이렇게 앞->뒤로 쓰고, 뒤->앞로 읽는게, 왜 그럴까? 라는 생각이 들었다. 하지만 생각해보면 당연한게, 데이터를 모두 다 작성해야, 푸터에 적을 데이터가 완성되기 때문에 앞->뒤 방향이고, 데이터를 읽을 때는 푸터에서 내가 접근할 데이터의 정보가 담긴 곳을 찾아야 하기 때문에 뒤->앞 순서로 접근하게 되는 것이다.
데이터 섹션: Row Group과 Column Chunk
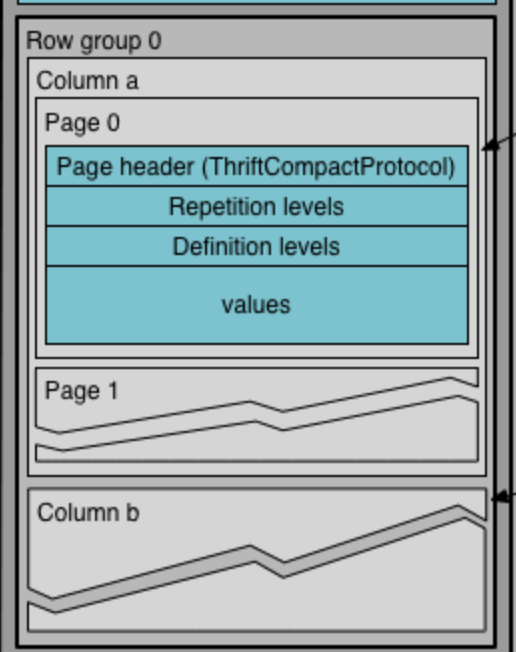
데이터 섹션에 데이터가 저장될 때, 전체 행을 N개 청크로 나눠서 저장하는데, 이걸 Row Group이라고 한다.
어? 그런데 Parquet는 columnar 포맷이라고 알고 있는데, 이렇게 Row 단위로 데이터를 저장해도 되는 건가?
Columnar 포맷은 같은 컬럼의 값들이 연속된 메모리/디스크 공간에 저장된다는 걸 만족한다는 거다. 이 조건은 Row Group 단위로 데이터를 저장해도 유지 된다. 왜냐하면, 컬럼 데이터는 Row Group 내에서 컬럼 값이 연속적으로 배치된 Chunk Chunk로 저자오디기 때문이다.
즉, Row Group은 columnar를 포기한 것이 아니라 현실적인 제약 때문에 이렇게 나눈 것이다. 만약 Row Group 없이 파일 전체를 하나의 컬럼 덩어리로 만들면, 1억 행차리 테이블의 컬럼 하나를 처리할 때, 수십 GB를 통째로 메모리에 올려야 할 수도 있다. Parquet는 Row Group으로 나뉘어져 있기 때문에, executor/worker에서 적정한 수준으로(ex: 128mb)씩 나눠서 처리할 수 있다.
10만 행의 데이터가 있다고 했을 때, Row Group은 128mb 단위로 분할 된다. 즉, 행 수가 아니라 실제 물리 데이터의 크기를 기준으로 나눠진다. 이건 기본값이고, Spark에서 df.write.parquet() 할 때, spark conf를 조정해서 변경할 수도 있다.
parquet.block.size(default: 128 * 1024 * 1024) 이 값을 조정하면 된다.
여기까지 읽었다면, 이미 알겠지만 Row Group 내에서 컬럼 데이터는 Column Chunk라고 컬럼 별로 분리되어 저장된다.
그런데, 이 Column Chunk도 Page라는 단위로 한번더 나뉘어서 저장된다.
데이터 섹션: Column Chunk와 Page
컬럼 데이터를 저장할 때도 데이터는 Page 단위로 잘라서 저장된다. Page 하나의 크기를 1mb로 잡고 Column Chunk를 나눈다는 것이다.
Spark에서 parquet write를 할 때, 데이터를 gz 압축해서 저장할지 snappy, lz4 압축해서 저장할지 고민하게 되는데, 이 압축이 적용되는 지점도 Page 레벨이다.
단, Page 하나의 크기가 1mb로 분할된다는 건 압축 전 크기를 기준으로 한다.
Page 사이즈도 조정할 수 있는데, Spark에서 parquet.page.size로 조정한다. 이 값도 압축 전 사이즈를 기준으로 한다.
데이터 섹션: Page 내부 구조

Page 내부도 생각보다 복잡하다 ㅋㅋ… 하나의 Page를 쉽게 관리하기 위해 메타데이터와 데이터 영역이 나뉜다.
데이터 영역이야 뭐, 데이터가 저장되는 곳이라 넘어가면 되고, 메타데이터 영역은 Header + Repetition Level + Definition Level로 순서로 구성된다.
일단 Definition Level이 이해하기 쉬우니 이것부터 살펴보면, 요건 Page에 저장한 데이터에 null 값이 어디어디에 있는지 표시하는 bit array다. N번째 위치의 데이터가 null이냐 아니냐를 본다. 그래서 null 기반 필터를 할 때, null count를 할 때는 실제 데이터를 안 읽고 Definition Level을 보고 데이터를 접근하고 null count를 세면 된다.
Repetition Level은 Page에 저장된 nested 포맷의 데이터를 표현하는데 쓰인다. 지금은 STRUCT나 ARRAY, VARIANT 타입일 때 쓸모가 있는 녀석이라고만 알고 넘어가자. 별도 포스트에서 어떻게 쓰이는지 설명할 예정이다. 일단은 일반 Primitive 타입들에서는 Reptition Level이 모두 bit zero인 bit array로 세팅 된다고 이해하자.
마지막으로 Page Header에는 이 Page가 어떤 타입인지, 압축 전 크기, 압축 후 크기, 이 Page에 담긴 row 수, rep/def level의 인코딩 방식, Page Values 데이터의 인코딩 방식 등등의 내용이 담긴다.
Page Header에 대한 내용은 좀 길어질 것 같고 중요한 내용이라서 별도 포스트로 분리한다.
푸터 섹션
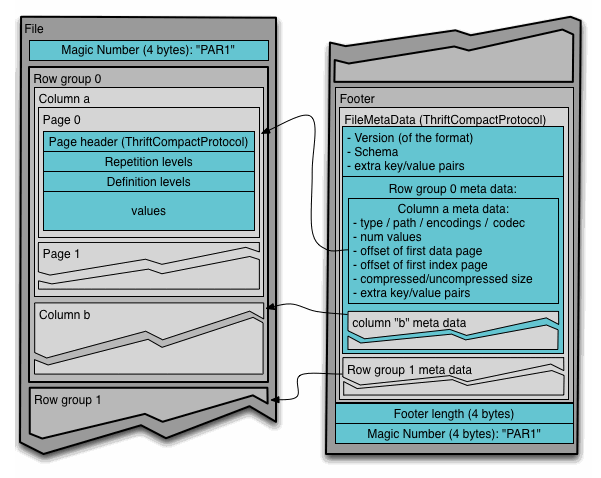
Thrift Binary로 직렬화 되어 있다 이런 내용은 지금 중요하지 않고, 큰 그림만 살펴보자면,
- Parquet Schema
- 컬럼명, 컬럼 타입
- nullable 여부
- nested 구조 여부
- Row Group의 목록
- 각 Row Group이 파일 내 offset 어디에 위치해 있는지
- 전체 크기
- 행 수
- Column Chunk의 정보
- Row Group 내 offset 어디에 위치해 있는지
- 압축 전/후 크기
- 압축 방식
- 인코딩 방식
- Key-value metadata
- 자유 형식의 메타데이터 key-value
- Spark에서 parquet write 했다면, Spark 버전 정보가 담기고
- Iceberg에서 쓴 경우, snapshot id, sequence number 등이 담김.
Thrift Binary로 직렬화 되어 있다라는 건, Parquet 포맷의 개발 당시에 Thrift 포맷이 이미 검증된 직렬화 포맷이었기 때문. Thrift는 JSON, XML 대비 크기가 작고 파싱이 빨랐었음.
맺음말
암튼 이렇게 Parquet 포맷에 대한 개요를 살펴보았다. 글을 적으면서 내가 Parquet 포맷에 대해 가지고 있던 막막함이 조금 해소된 것 같다 😇
이제 내가 잘 모르고 있는 파트인 Encoding, Repetition Level, Variant에 대해 정리해보려고 한다.